9. Dimensionality Reduction#
Key takeaways
PCA is a linear dimensionality reduction technique that creates uncorrelated principal components ranked by variance, making it interpretable and efficient but less suitable for visualizing highly non-linear scRNA-seq data.
UMAP is a non-linear method that constructs and optimizes graph representations to preserve both local and global data structures, making it highly effective for visualization and clustering of single-cell data.
Environment setup
Install conda:
Before creating the environment, ensure that conda is installed on your system.
Save the yml content:
Copy the content from the yml tab into a file named
environment.yml.
Create the environment:
Open a terminal or command prompt.
Run the following command:
conda env create -f environment.yml
Activate the environment:
After the environment is created, activate it using:
conda activate <environment_name>
Replace
<environment_name>with the name specified in theenvironment.ymlfile. In the yml file it will look like this:name: <environment_name>
Verify the installation:
Check that the environment was created successfully by running:
conda env list
name: preprocessing
channels:
- bioconda
- conda-forge
dependencies:
- conda-forge::ipywidgets=8.1.5
- conda-forge::leidenalg=0.10.2
- conda-forge::numba=0.61.0
- conda-forge::python=3.12.9
- conda-forge::r-base=4.3.3
- conda-forge::r-soupx=1.6.2
- conda-forge::r-sctransform=0.4.1
- conda-forge::r-glmpca=0.2.0
- conda-forge::rpy2=3.5.11
- conda-forge::scanpy=1.11.1
- conda-forge::session-info=1.0.0
- bioconda::anndata2ri=1.3.2
- bioconda::bioconductor-scdblfinder=1.16.0
- bioconda::bioconductor-scry=1.14.0
- bioconda::bioconductor-scran=1.30.0
- bioconda::bioconductor-glmgampoi=1.14.0
- pip
- pip:
- lamindb[bionty,jupyter]
Get data and notebooks
This book uses lamindb to store, share, and load datasets and notebooks using the theislab/sc-best-practices instance. We acknowledge free hosting from Lamin Labs.
Install lamindb
Install the lamindb Python package:
pip install lamindb
Optionally create a lamin account
Sign up and log in following the instructions
Verify your setup
Run the
lamin connectcommand:
import lamindb as ln ln.Artifact.connect("theislab/sc-best-practices").df()
You should now see up to 100 of the stored datasets.
Accessing datasets (Artifacts)
Search for the datasets on the Artifacts page
Load an Artifact and the corresponding object:
import lamindb as ln af = ln.Artifact.connect("theislab/sc-best-practices").get(key="key_of_dataset", is_latest=True) obj = af.load()
The object is now accessible in memory and is ready for analysis. Adapt the
ln.Artifact.connect("theislab/sc-best-practices").get("SOMEIDXXXX")suffix to get respective versions.Accessing notebooks (Transforms)
Search for the notebook on the Transforms page
Load the notebook:
lamin load <notebook url>
which will download the notebook to the current working directory. Analogously to
Artifacts, you can adapt the suffix ID to get older versions.
scRNA-seq is a high-throughput sequencing technology that produces datasets with high dimensions in the number of cells and genes. Therefore, scRNA-seq data suffers from the ‘curse of dimensionality’.
Curse of dimensionality
The Curse of dimensionality was first brought up by R. Bellman [Bellman et al., 1957] and describes that, in theory, high-dimensional data contains more information, but in practice this is not the case. Higher-dimensional data often contains more noise and redundancy, and therefore, adding more information does not provide benefits for downstream analysis steps.
Not all genes are informative and therefore not all genes are essential for tasks such as clustering. We already aimed to reduce the dimensionality of the data with feature selection. As a next step, we will further reduce the dimensions of single-cell RNA-seq data with dimensionality reduction algorithms. These algorithms are an important step during preprocessing to reduce the data complexity and for visualization.
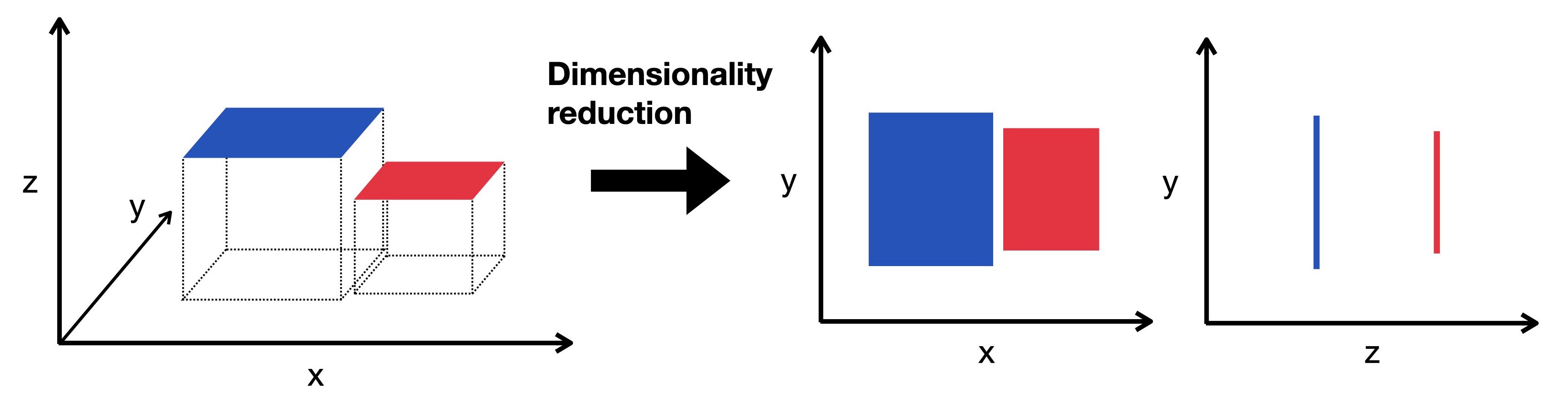
Fig. 9.1 Dimensionality reduction embeds the high-dimensional data into a lower-dimensional space. The low-dimensional representation still captures the underlying structure of the data while having as few dimensions as possible. Here we visualize a three-dimensional object projected into two dimensions.#
Xing et al. compared in an independent comparison the stability, accuracy, and computing cost of 10 different dimensionality reduction methods [Xiang et al., 2021]. They propose to use t-distributed stochastic neighbor embedding (t-SNE) as it yielded the best overall performance. Uniform manifold approximation and projection (UMAP) showed the highest stability and separated the original cell populations best. An additional dimensionality reduction worth mentioning in this context is principal component analysis (PCA), which is still widely used.
Generally, t-SNE and UMAP are very robust and mostly equivalent if specific choices for the initialization are selected [Kobak and Berens, 2019].
All aforementioned methods are implemented in scanpy.
Now we start with importing all required Python packages and load the dataset after quality control, normalization, and feature selection.
import lamindb as ln
import scanpy as sc
# Suppress verbose logging from Scanpy
sc.settings.verbosity = 0
# Set figure parameters for clean, minimal plots
sc.settings.set_figure_params(dpi=80, facecolor="white", frameon=False)
assert ln.setup.settings.instance.slug == "theislab/sc-best-practices"
ln.track()
af = ln.Artifact.connect("theislab/sc-best-practices").get(
key="preprocessing_visualization/s4d8_feature_selection.h5ad", is_latest=True
)
adata = af.load()
We will use a normalized representation of the dataset for dimensionality reduction and visualization, specifically the shifted logarithm.
Why should you use normalized data for dimensionality reduction?
First, gene expression data is typically heavily right-skewed with many zeros and a few highly expressed genes. Log transformation helps normalize this distribution, making it more symmetric and reducing the impact of extreme values. This prevents highly expressed genes from dominating any distance calculations.
Second, biological signals in expression data often follow multiplicative rather than additive patterns. Log transformation converts multiplicative relationships to additive ones, which most dimensionality reduction algorithms (PCA, t-SNE, UMAP) are designed to detect.
Third, variance in raw expression data typically scales with mean expression levels. Log transformation stabilizes this variance, preventing highly expressed genes from dominating the analysis. For zero values (dropout events common in single-cell data), a pseudocount is typically added before log transformation (log1p) to avoid mathematical errors.
adata.X = adata.layers["scran_normalization"]
We start with:
9.1. PCA#
In our dataset, each cell is a vector of a n_var-dimensional vector space spanned by some orthonormal basis.
As scRNA-seq suffers from the ‘curse of dimensionality’, we know that not all features are important to understand the underlying dynamics of the dataset and that there is an inherent redundancy[Grün et al., 2014].
PCA creates a new set of uncorrelated variables, so-called principal components (PCs), via an orthogonal transformation of the original dataset.
The PCs are linear combinations of features in the original dataset and are ranked in decreasing order of variance to define the transformation.
In the ranking, the first PC typically captures the greatest amount of variance.
PCs with the lowest variance are discarded to effectively reduce the dimensionality of the data without losing information.
PCA offers the advantage that it is highly interpretable and computationally efficient. However, as scRNA-seq datasets are rather sparse due to dropout events and therefore highly non-linear, visualization with the linear dimensionality reduction technique PCA is not very appropriate. PCA is typically used to select the top 10-50 PCs, which are used for downstream analysis tasks.
# setting highly variable as highly deviant to use scanpy 'use_highly_variable' argument in sc.pp.pca
adata.var["highly_variable"] = adata.var["highly_deviant"]
sc.pp.pca(adata, svd_solver="arpack", mask_var="highly_variable")
sc.pl.pca_scatter(adata, color="total_counts")
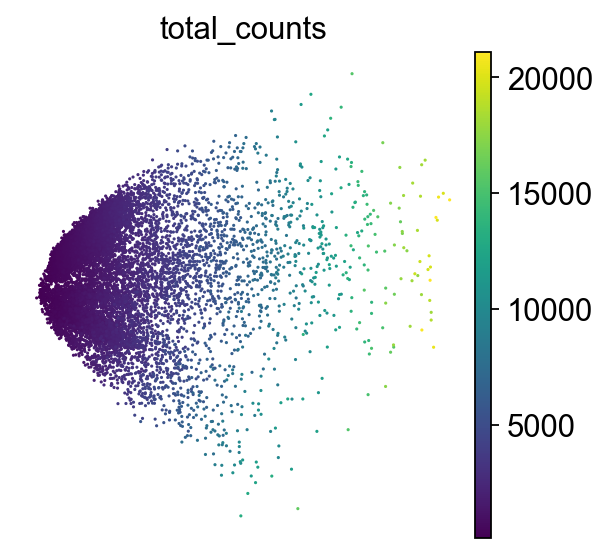
How to understand a PCA scatter plot
PCA looks for the directions in the data where the values of the cells (or samples) differ the most.
Axes: PC1 and PC2 are the first and second principal components(directions). PC1 is the direction where the data is most spread out, and PC2 is the next most variable direction, perpendicular to PC1.
Points: Each point is a single cell. The color of each point represents the total number of transcripts (UMIs) detected in that cell.
By projecting the data onto PC1 and PC2, we capture most of the meaningful variation in fewer dimensions.
Although we do not aim to interpret biological meaning directly from this PCA plot at this stage, we can observe cellular heterogeneity: cells with similar expression profiles tend to cluster together, which may reflect different cell types or states.
9.2. t-SNE#
t-SNE is a graph based, non-linear dimensionality reduction technique which projects the high dimensional data onto 2D or 3D components. The method defines a Gaussian probability distribution based on the high-dimensional Euclidean distances between data points. Subsequently, a Student t-distribution is used to recreate the probability distribution in a low dimensional space where the embeddings are optimized using gradient descent.
sc.tl.tsne(adata, use_rep="X_pca")
sc.pl.tsne(adata, color="total_counts")
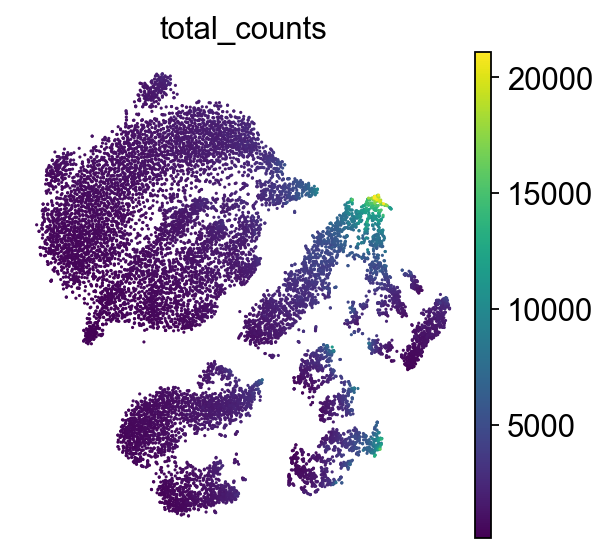
How to understand t-SNE plot
Axes have no meaning!
Points: Each point represents a single cell. Color represents the total number of transcripts (UMIs) detected in that cell.
This plot helps reveal cellular subpopulations: tight clusters may correspond to distinct cell types or states. Unlike PCA, which preserves global variance, t-SNE emphasizes local structure. For this reason, it is best practice to initialize t-SNE from PCA to reduce noise and improve stability of the embedding.
9.3. UMAP#
UMAP is a graph-based, non-linear dimensionality reduction technique and is principally similar to t-SNE. It constructs a high-dimensional graph representation of the dataset and optimizes the low-dimensional graph representation to be as structurally similar as possible to the original graph.
We first calculate PCA and subsequently create a neighborhood graph based on our data.
sc.pp.neighbors(adata)
sc.tl.umap(adata)
sc.pl.umap(adata, color="total_counts")
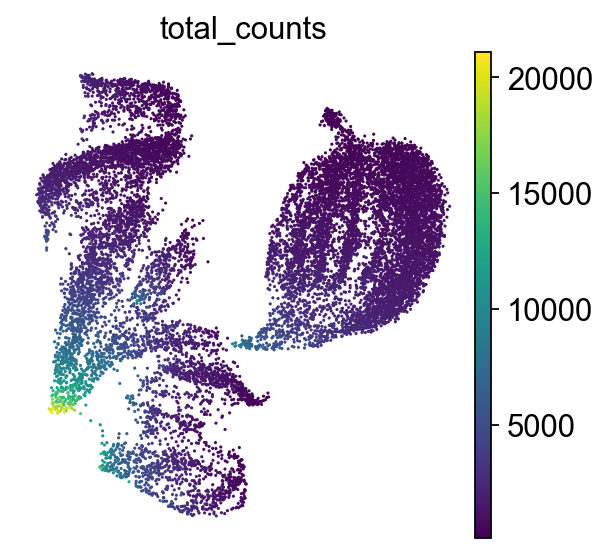
How to understand a UMAP plot
Axes have no meaning!
Points: Each point represents a single cell.
Color indicates the total number of transcripts (UMIs) detected in that cell.
UMAP emphasizes both local and some global structure, often better preserving the overall shape of the data compared to t-SNE, i.e. similar clusters are closer together. It constructs a neighborhood graph based on PCA-reduced data, then optimizes a low-dimensional layout that reflects relationships in the original high-dimensional space. UMAP is widely used for visualizing cell clusters and trajectories in single-cell data.
9.4. Inspecting quality control metrics#
We can now also inspect the quality control metrics we calculated previously in our PCA, TSNE or UMAP plot and potentially identify low-quality cells.
sc.pl.umap(
adata,
color=["total_counts", "pct_counts_mt", "scDblFinder_score", "scDblFinder_class"],
)
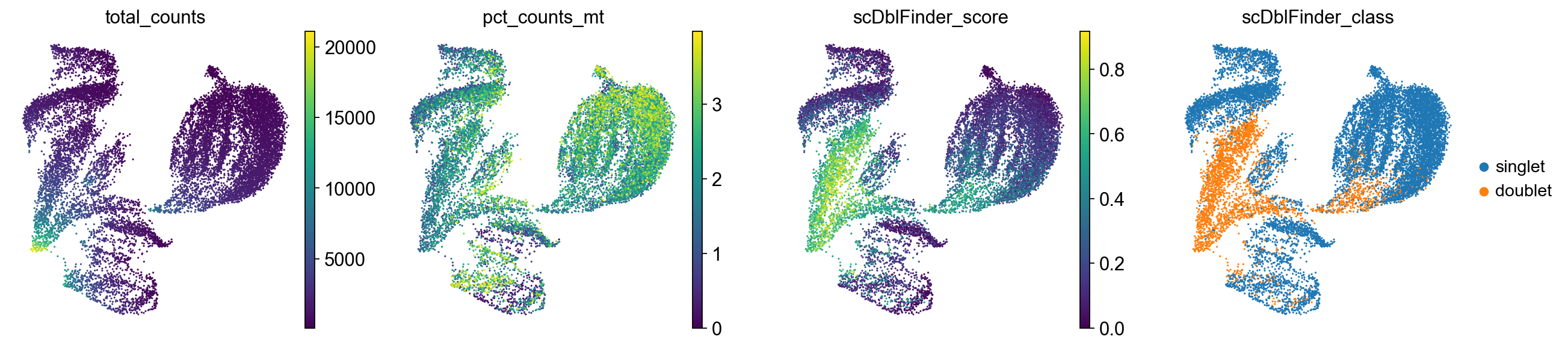
Cells with a high doublet score are projected to the same region in the UMAP. We will keep them in the dataset for now but generally this suggests to potentially re-visit the quality control strategy again to ensure that as few doublets as possible are retained.
af = ln.Artifact(
adata,
key="preprocessing_visualization/s4d8_dimensionality_reduction.h5ad",
description="anndata after dimensionality reduction",
).save()
af
9.5. References#
R. Bellman, R.E. Bellman, and Rand Corporation. Dynamic Programming. Rand Corporation research study. Princeton University Press, 1957. URL: https://books.google.de/books?id=rZW4ugAACAAJ.
Dominic Grün, Lennart Kester, and Alexander Van Oudenaarden. Validation of noise models for single-cell transcriptomics. Nature methods, 11(6):637–640, 2014.
Dmitry Kobak and Philipp Berens. The art of using t-sne for single-cell transcriptomics. Nature Communications, 10(1):5416, Nov 2019. URL: https://doi.org/10.1038/s41467-019-13056-x, doi:10.1038/s41467-019-13056-x.
Ruizhi Xiang, Wencan Wang, Lei Yang, Shiyuan Wang, Chaohan Xu, and Xiaowen Chen. A comparison for dimensionality reduction methods of single-cell term`rna`-seq data. Frontiers in Genetics, 2021. URL: https://www.frontiersin.org/article/10.3389/fgene.2021.646936, doi:10.3389/fgene.2021.646936.
9.6. Contributors#
We gratefully acknowledge the contributions of:
9.6.2. Reviewers#
Lukas Heumos