13. Annotation#
Key takeaways
Cell annotation is the process of labeling groups of cells based on known or unknown cellular phenotypes, which is crucial for understanding the cellular composition of your data.
Manual annotation relies on known marker genes and clustering, but it can be subjective and labor-intensive.
Automated annotation methods, such as CellTypist and scArches, offer faster and more scalable alternatives, but their accuracy depends on the quality of the reference data and the similarity between the reference and the query dataset.
Environment setup
Install conda:
Before creating the environment, ensure that conda is installed on your system.
Save the yml content:
Copy the content from the yml tab into a file named
environment.yml.
Create the environment:
Open a terminal or command prompt.
Run the following command:
conda env create -f environment.yml
Activate the environment:
After the environment is created, activate it using:
conda activate <environment_name>
Replace
<environment_name>with the name specified in theenvironment.ymlfile. In the yml file it will look like this:name: <environment_name>
Verify the installation:
Check that the environment was created successfully by running:
conda env list
name: annotation
channels:
- conda-forge
- bioconda
dependencies:
- conda-forge::python=3.12.9
- conda-forge::ipykernel=6.29.5
- conda-forge::scanpy=1.12.0
- conda-forge::leidenalg=0.10.2
- conda-forge::umap-learn=0.5.7
- conda-forge::pynndescent=0.5.13
- conda-forge::scvi-tools=1.3.1
- conda-forge::anndata=0.11.4
- pip
- pip:
- scarches==0.6.1
- celltypist==1.6.3
- lamindb==2.3.1
- pandas==2.2.3
Get data and notebooks
This book uses lamindb to store, share, and load datasets and notebooks using the theislab/sc-best-practices instance. We acknowledge free hosting from Lamin Labs.
Install lamindb
Install the lamindb Python package:
pip install lamindb
Optionally create a lamin account
Sign up and log in following the instructions
Verify your setup
Run the
lamin connectcommand:
import lamindb as ln ln.Artifact.connect("theislab/sc-best-practices").df()
You should now see up to 100 of the stored datasets.
Accessing datasets (Artifacts)
Search for the datasets on the Artifacts page
Load an Artifact and the corresponding object:
import lamindb as ln af = ln.Artifact.connect("theislab/sc-best-practices").get(key="key_of_dataset", is_latest=True) obj = af.load()
The object is now accessible in memory and is ready for analysis. Adapt the
lamindb.Artifact.connect("theislab/sc-best-practices").get("SOMEIDXXXX")suffix to get respective versions.Accessing notebooks (Transforms)
Search for the notebook on the Transforms page
Load the notebook:
lamin load <notebook url>
which will download the notebook to the current working directory. Analogously to
Artifacts, you can adapt the suffix ID to get older versions.
13.1. Motivation#
To understand your data better and make use of existing knowledge, it is important to figure out the “cellular identity” of each of the cells in your data. The process of labeling groups of cells in your data based on known (or sometimes unknown) cellular phenotypes is called “cell annotation”. Whereas there are many ways to annotate your cells (e.g. based on batch, disease, sex and more), in this notebook we will focus on the annotation of “cell types”.
A cell type is a cellular phenotype that is robust across datasets, identifiable by specific marker genes or proteins, and tied to a distinct biological function. A classic example is the plasma B cell — a white blood cell that secretes antibodies and can be identified by characteristic markers.
However, like with any categorization the size of categories and the borders drawn between them are partly subjective and can change over time, e.g. because new technologies allow for a higher resolution view of cells, or because specific “sub-phenotypes” that were not considered biologically meaningful are found to have important biological implications (see e.g. [Kadur Lakshminarasimha Murthy et al., 2022]). Cell types are therefore often further classified into “subtypes” or “cell states” (e.g. activated versus resting) and some researchers use the term “cell identity” to avoid this sometimes arbitrary distinction. For a more detailed discussion of this topic, we recommend the review by Wagner et al. [Wagner et al., 2016] and the recently published review by Zeng [Zeng, 2022].
Similarly, multiple cell types can be part of a single continuum, where one cell type might transition or differentiate into another. For example, in hematopoiesis cells differentiate from a stem cell into a specific immune cell type. Although hard borders between early and late stages of this differentiation are often drawn, the state of these cells can more accurately be described by the differentiation coordinate between the less and more differentiated cellular phenotypes.
There are multiple ways to annotate cells. We will give an overview of the most widely used approaches below. As we are working with transcriptomic data, each of these methods is ultimately based on the expression of specific genes or gene sets, or general transcriptomic similarity between cells.
13.2. Environment setup#
import shutil
import sys
from pathlib import Path
import celltypist
import lamindb as ln
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pandas.core.indexes.base as pandas_indexes_base
import scanpy as sc
import scarches as sca
import seaborn as sns
from celltypist import models
from scipy.sparse import csr_matrix
ln.connect("theislab/sc-best-practices")
ln.track("BnpvfJLWjHuE")
We will continue working with the scRNA-seq dataset that we earlier preprocessed and will now annotate it.
Set figure parameters:
sc.set_figure_params(figsize=(5, 5))
13.3. Load data#
Let’s read in the toy dataset we will use for this tutorial. It includes a single sample (“site4-donor8”) of the data also used in other parts of the book. Moreover, cells that didn’t pass QC have already been removed.
af = ln.Artifact.get(key="cellular_structure/s4d8_clustered.h5ad", is_latest=True)
adata = af.load(is_run_input=False)
... synchronizing s4d8_clustered.h5ad: 100.0%
13.4. Manual annotation#
The classical or oldest way to perform cell type annotation is based on a single or small set of marker genes known to be associated with a particular cell type. This approach dates back to “pre-scRNA-seq times”, when single-cell data was low-dimensional (e.g., FACS data with gene panels consisting of no more than 30-40 genes). However, when no unique markers exist for a specific cell type, this approach can quickly become challenging and less objective, with combinations of markers or expression thresholds necessary for proper annotation. A robust set of marker genes and prior knowledge or annotation experience can help here, but the approach comes with the risk of unclear and subjective decision-making.
For manual annotation, the data is usually clustered before annotation, so that we can annotate groups of cells instead of making a per-cell call. This is not only less laborious but also more robust to noise: a single cell might not have a count for a specific marker even if it was expressed in that cell, simply due to the inherent sparsity of single-cell data. Clustering enables the detection of cells highly similar in overall gene expression and can therefore account for drop-outs at the single-cell level.
Finally, there are two angles from which to approach the marker-gene-based annotation. One option is to work from a table of marker genes for all the cell types you expect in your data and check in which clusters those genes are expressed. The other option is to check which genes are highly expressed in the clusters you defined and then check if they are associated with known cell types or states. If necessary, one can move back and forth between those approaches. We will show examples of both below.
13.4.1. From markers to cluster annotation#
First, we list a set of markers for cell types in the bone marrow that is based on literature: previous papers that study specific cell types and subtypes and report marker genes for those cell types. Note that markers at the protein level (e.g., used for FACS) sometimes do not work as well in transcriptomic data; hence, using markers from RNA-based papers is often more likely to work. Moreover, sometimes markers in one dataset do not turn out to work as well in other datasets. Ideally, a marker set is therefore validated across multiple datasets. It is often useful to work together with experts: as a bioinformatician, try to team up with a biologist who has more extensive knowledge of the tissue, the biology, the expected cell types and markers, etc.
# keys: cell types or populations, values: lists of marker genes
marker_genes = {
"CD14+ Mono": ["FCN1", "CD14"],
"CD16+ Mono": ["TCF7L2", "FCGR3A", "LYN"],
"ID2-hi myeloid prog": [
"CD14",
"ID2",
"VCAN",
"S100A9",
"CLEC12A",
"KLF4",
"PLAUR",
],
"cDC1": ["CLEC9A", "CADM1"],
"cDC2": [
"CST3",
"COTL1",
"LYZ",
"DMXL2",
"CLEC10A",
"FCER1A",
], # Note: DMXL2 should be negative
"Normoblast": ["SLC4A1", "SLC25A37", "HBB", "HBA2", "HBA1", "TFRC"],
"Erythroblast": ["MKI67", "HBA1", "HBB"],
"Proerythroblast": [
"CDK6",
"SYNGR1",
"HBM",
"GYPA",
], # Note HBM and GYPA are negative markers
"NK": ["GNLY", "NKG7", "CD247", "GRIK4", "FCER1G", "TYROBP", "KLRG1", "FCGR3A"],
"ILC": ["ID2", "PLCG2", "GNLY", "SYNE1"],
"Lymph prog": [
"VPREB1",
"MME",
"EBF1",
"SSBP2",
"BACH2",
"CD79B",
"IGHM",
"PAX5",
"PRKCE",
"DNTT",
"IGLL1",
],
"Naive CD20+ B": ["MS4A1", "IL4R", "IGHD", "FCRL1", "IGHM"],
"B1 B": [
"MS4A1",
"SSPN",
"ITGB1",
"EPHA4",
"COL4A4",
"PRDM1",
"IRF4",
"CD38",
"XBP1",
"PAX5",
"BCL11A",
"BLK",
"IGHD",
"IGHM",
"ZNF215",
], # Note IGHD and IGHM are negative markers
"Transitional B": ["MME", "CD38", "CD24", "ACSM3", "MSI2"],
"Plasma cells": ["MZB1", "HSP90B1", "FNDC3B", "PRDM1", "IGKC", "JCHAIN"],
"Plasmablast": ["XBP1", "RF4", "PRDM1", "PAX5"], # Note PAX5 is a negative marker
"CD4+ T activated": ["CD4", "IL7R", "TRBC2", "ITGB1"],
"CD4+ T naive": ["CD4", "IL7R", "TRBC2", "CCR7"],
"CD8+ T": ["CD8A", "CD8B", "GZMK", "GZMA", "CCL5", "GZMB", "GZMH", "GZMA"],
"T activation": ["CD69", "CD38"], # CD69 much better marker!
"T naive": ["LEF1", "CCR7", "TCF7"],
"pDC": ["GZMB", "IL3RA", "COBLL1", "TCF4"],
"G/M prog": ["MPO", "BCL2", "KCNQ5", "CSF3R"],
"HSC": ["NRIP1", "MECOM", "PROM1", "NKAIN2", "CD34"],
"MK/E prog": [
"ZNF385D",
"ITGA2B",
"RYR3",
"PLCB1",
], # Note PLCB1 is a negative marker
}
Negative markers
A negative marker is a gene not expressed in a specific cell type, used to exclude or distinguish it, whereas a positive marker is actively expressed to identify the cell type.
Subset to only the markers that were detected in our data. We will loop through all cell types and keep only the genes that we find in our adata object as markers for that cell type. This will prevent errors once we start plotting.
marker_genes_in_data = {}
for ct, markers in marker_genes.items():
markers_found = []
for marker in markers:
if marker in adata.var.index:
markers_found.append(marker)
marker_genes_in_data[ct] = markers_found
To see where these markers are expressed, we can work with a 2-dimensional visualization of the data, such as a UMAP. We calculate such an embedding here based on the scran-normalized count data, using only the highly deviant genes. Note that we first perform a PCA on the normalized counts to reduce the dimensionality of the data before we generate the UMAP.
To start we store our raw counts in .layers['counts'], so that we will still have access to them later if needed.
We then set our adata.X to the scran-normalized, log-transformed counts.
adata.layers["counts"] = adata.X
adata.X = adata.layers["scran_normalization"]
We furthermore set our adata.var.highly_variable to the highly deviant genes.
Scanpy uses this var column in downstream calculations, such as the PCA below.
adata.var["highly_variable"] = adata.var["highly_deviant"]
Now perform PCA. We use the highly deviant genes (set as “highly variable” above) to reduce noise and strengthen signal in our data and set number of components to the default n=50. 50 is on the high side for data of a single sample, but it will ensure that we don’t ignore important variation in our data.
sc.tl.pca(adata, n_comps=50, use_highly_variable=True)
Calculate the neighbor graph based on the PCs:
sc.pp.neighbors(adata)
And use that neighbor graph to calculate a 2-dimensional UMAP embedding of the data:
sc.tl.umap(adata)
Now show expression of the markers using the calculated UMAP. We’ll limit ourselves to B/plasma cell subtypes for this example. Note from the marker dictionary above that there are three negative markers in our list: IGHD and IGHM for B1 B, and PAX5 for plasmablasts, meaning that this cell type is expected not to or to lowly express those markers.
Let’s list the B cell subtypes we want to show the markers for:
B_plasma_cts = [
"Naive CD20+ B",
"B1 B",
"Transitional B",
"Plasma cells",
"Plasmablast",
]
And now plot one UMAP per marker for each of the B cell subtypes. Note that we can only plot the markers that are present in our data.
for ct in B_plasma_cts:
print(f"{ct.upper()}:") # print cell subtype name
sc.pl.umap(
adata,
color=marker_genes_in_data[ct],
vmin=0,
vmax="p99", # set vmax to the 99th percentile of the gene count instead of the maximum, to prevent outliers from making expression in other cells invisible. Note that this can cause problems for extremely lowly expressed genes.
sort_order=False, # do not plot highest expression on top, to not get a biased view of the mean expression among cells
frameon=False,
cmap="Reds", # or choose another color map e.g. from here: https://matplotlib.org/stable/tutorials/colors/colormaps.html
)
print("\n\n\n") # print white space for legibility
NAIVE CD20+ B:
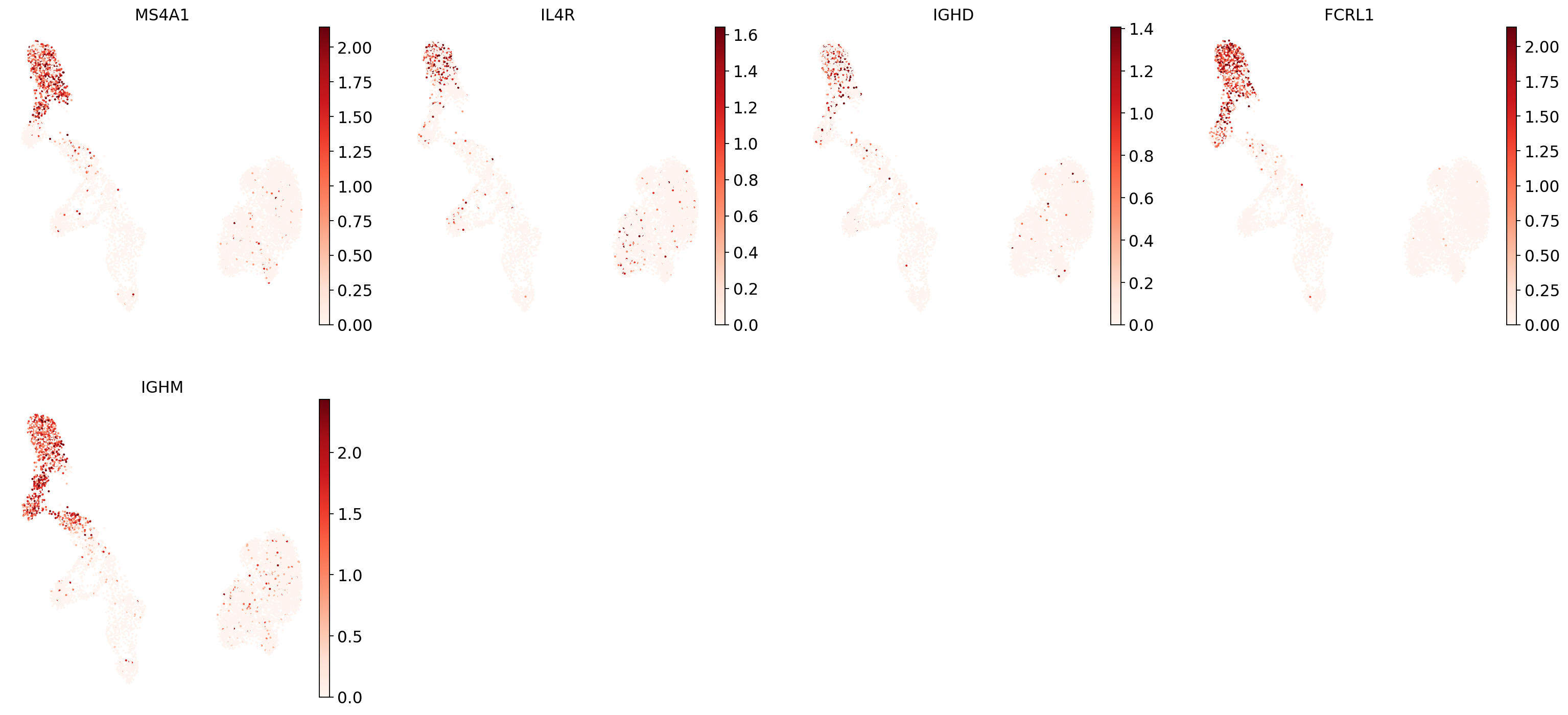
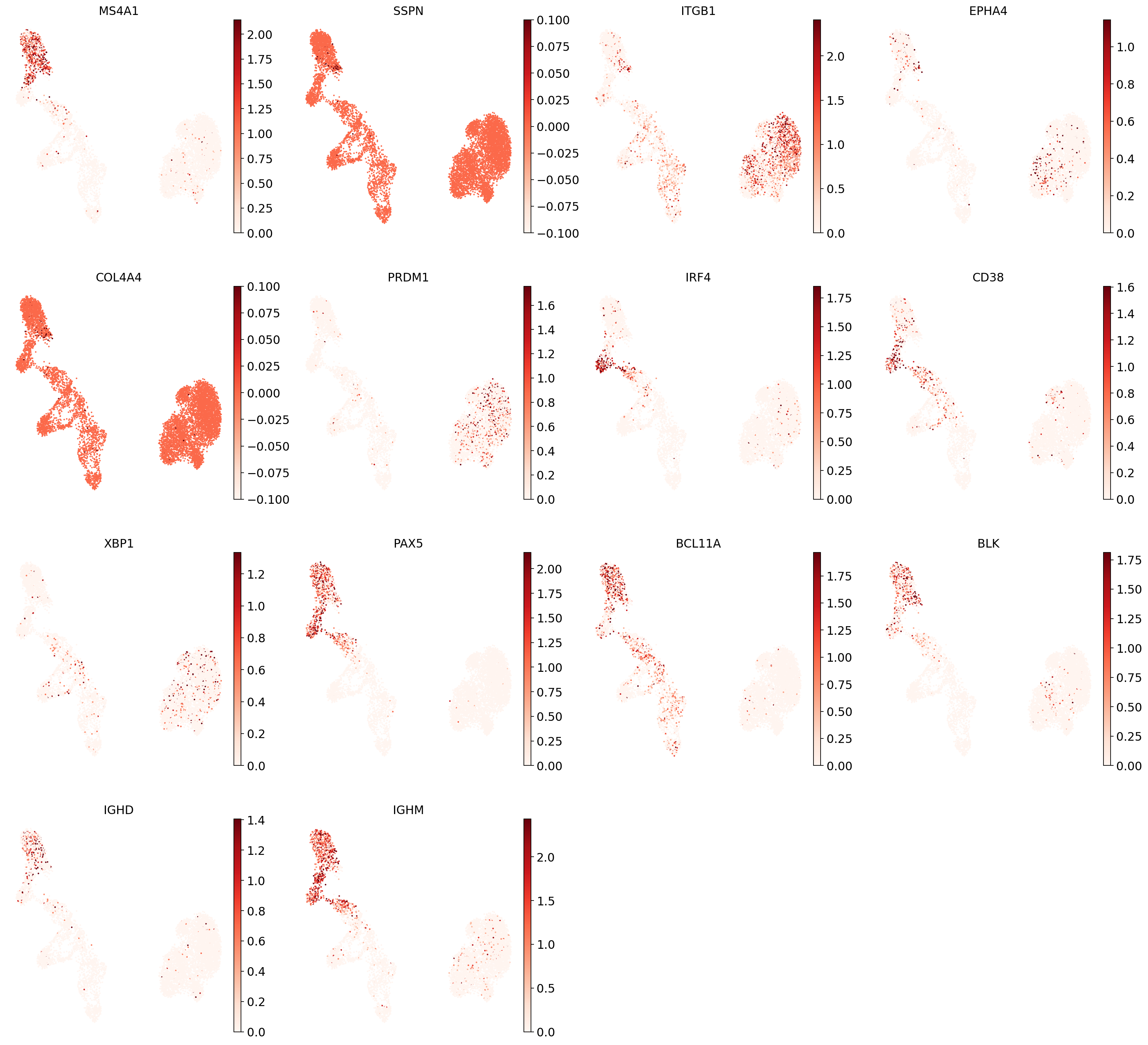
B1 B:
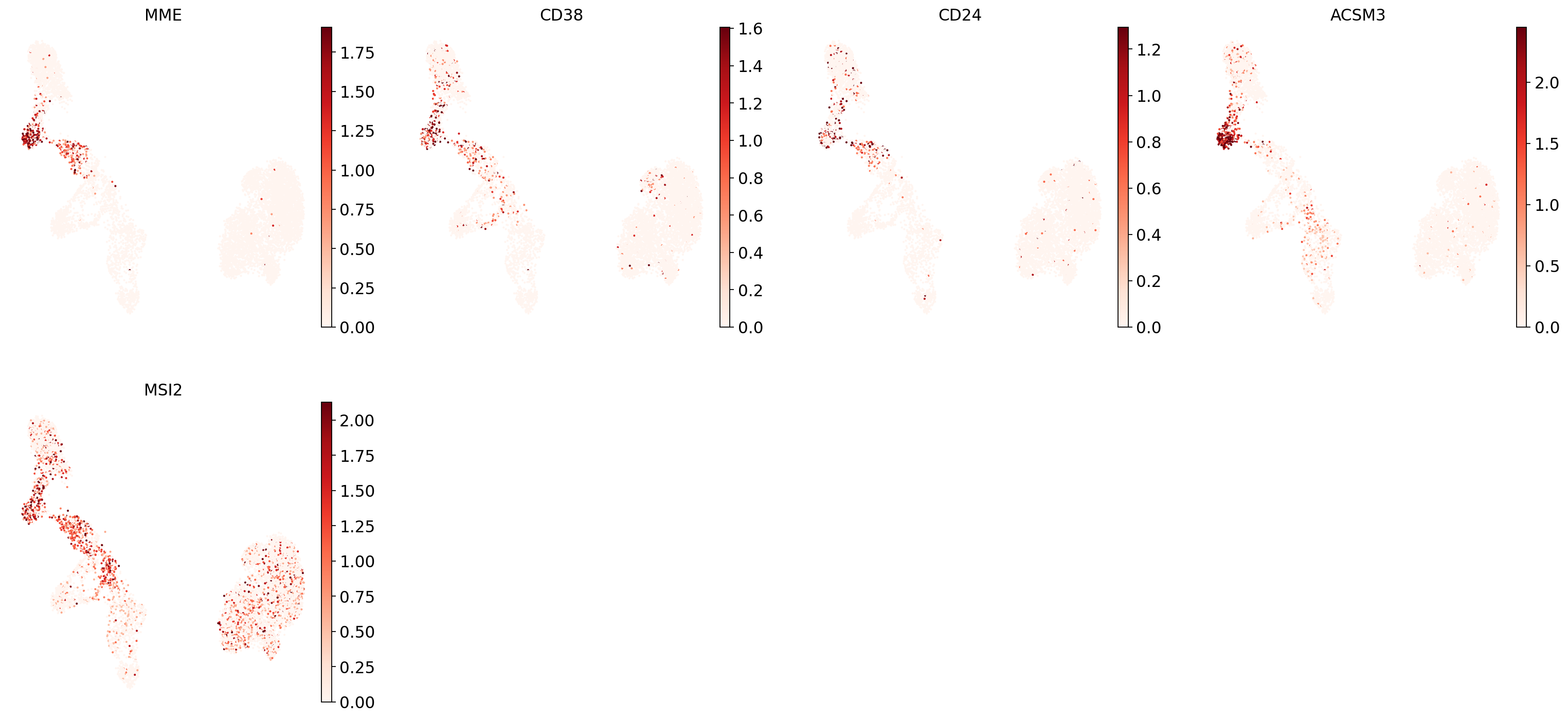
TRANSITIONAL B:
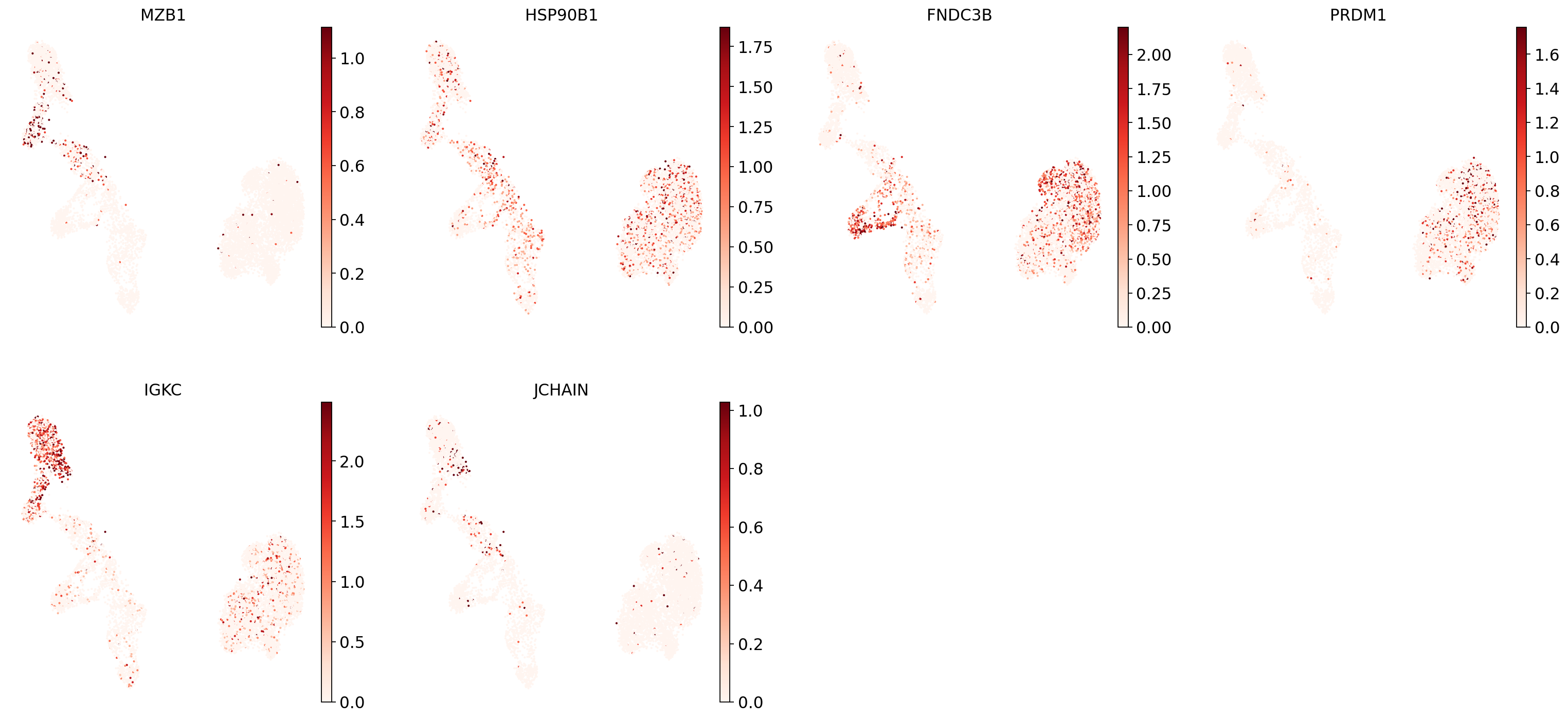
PLASMA CELLS:
PLASMABLAST:
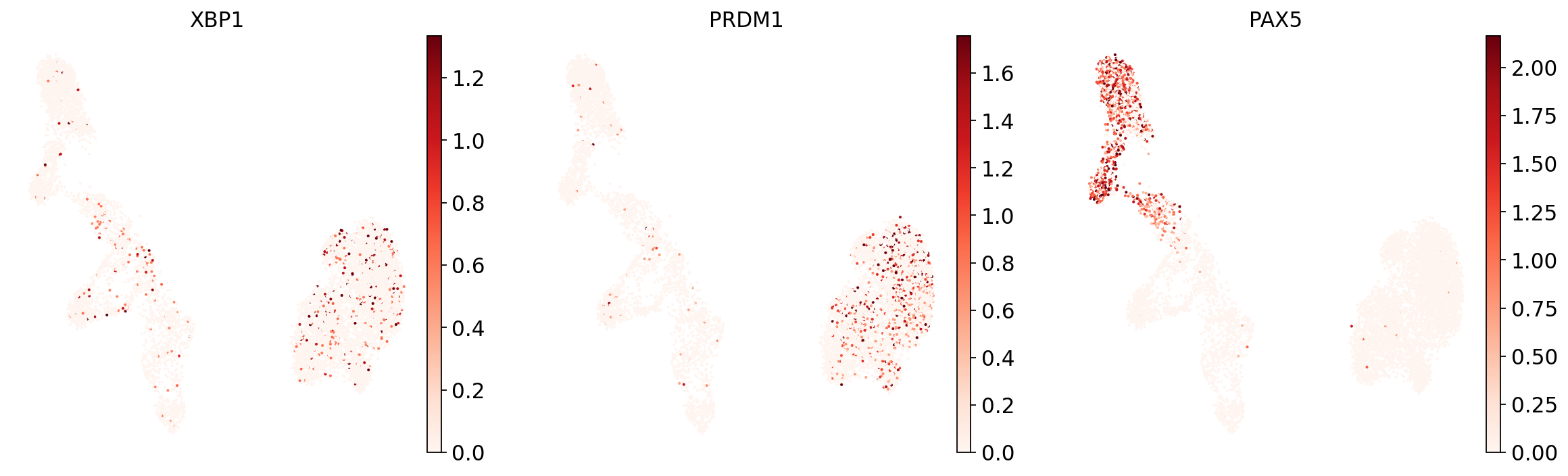
Even markers for a single cell type are often expressed in different subsets of the data, i.e. individual markers are often not uniquely expressed in a single cell type. Rather, it is the intersection of those subsets that will tell you where your cell type of interest is.
Of note is that markers are often sparsely expressed, i.e., it is often only a subset of cells of a cell type in which a marker was detected. This is due to the nature of scRNA-seq data: we only sequence a small subset of the total amount of RNA molecules in the cell, and due to this subsampling, we will sometimes not sample transcripts from specific genes in a cell even if they were expressed in that cell. Therefore, we do not annotate single cells based on a minimum expression threshold of, e.g., a set of markers. Instead, we first subdivide the data into groups of similar cells (i.e., “partition” the data) by clustering, thereby accounting for “missing transcripts” of single genes and rather grouping based on overall transcriptomic similarity. We can then annotate those clusters based on their overall marker expression patterns.
Let us cluster our data now. We will use the Leiden algorithm [Traag et al., 2019] as discussed in the Clustering chapter to define a grouping of our data into similar subsets of cells:
sc.tl.leiden(adata, resolution=1, key_added="leiden_1")
sc.pl.umap(adata, color="leiden_1")
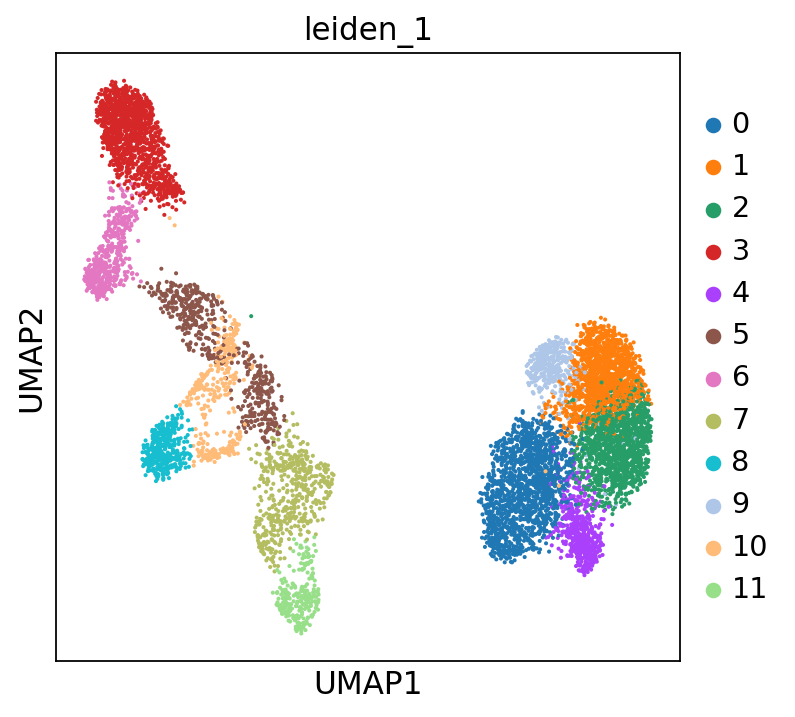
In case you want the partitioning to be finer, you can change the resolution to a higher level by changing the resolution parameter of the clustering:
sc.tl.leiden(adata, resolution=2, key_added="leiden_2")
You can also add the cluster numbers to the UMAP.
sc.pl.umap(adata, color="leiden_2", legend_loc="on data")
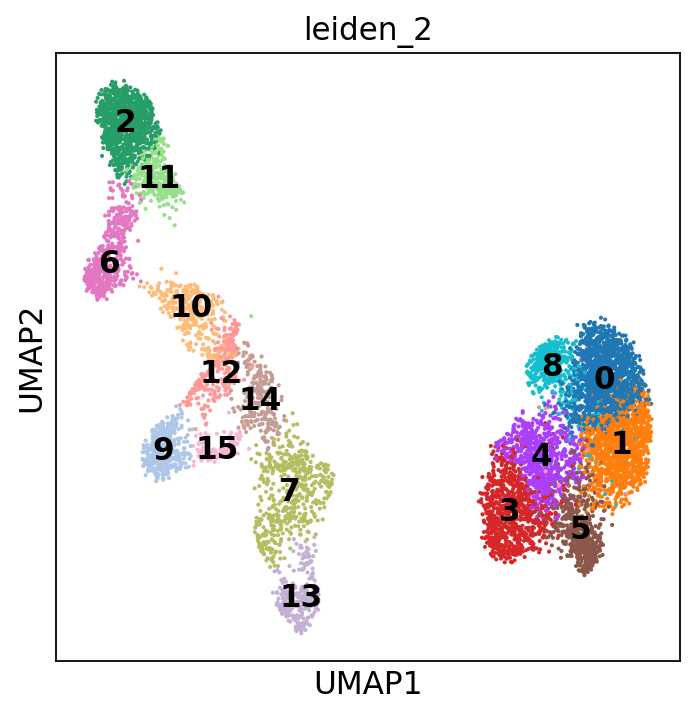
This clustering is much finer and, in some cases, will help you annotate the data with more detail. You can play around with the resolution parameter to find the setting that best captures the marker expression patterns you observe. In our case, we will stick to the original resolution:
sc.pl.umap(adata, color="leiden_1", legend_loc="on data")
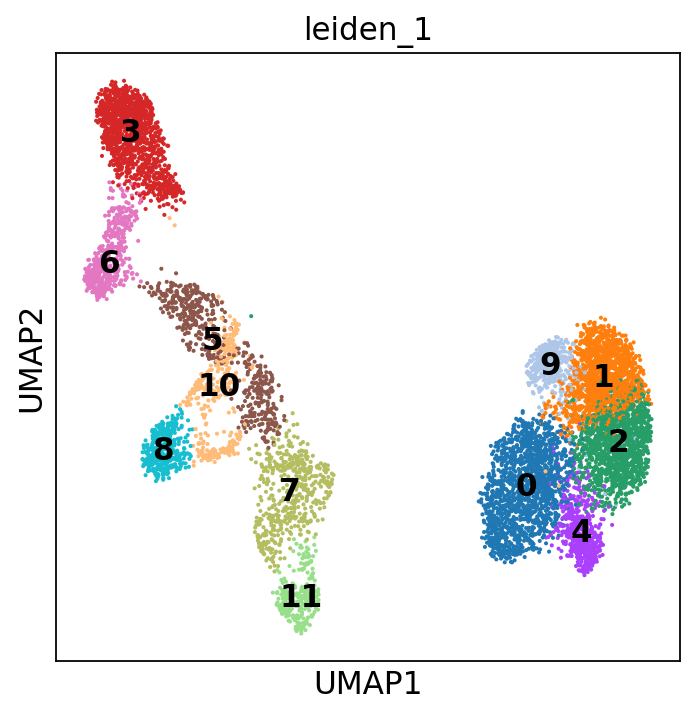
Scrolling back up, you will see that cluster 3 consistently expresses Naive CD20+ B cell markers, while cluster 6 consistently expresses Transitional B cell markers.
We can also visualize this using a dotplot:
B_plasma_markers = {
ct: [m for m in ct_markers if m in adata.var.index]
for ct, ct_markers in marker_genes.items()
if ct in B_plasma_cts
}
sc.pl.dotplot(
adata,
groupby="leiden_1",
var_names=B_plasma_markers,
standard_scale="var", # standard scale: normalize each gene to range from 0 to 1
)
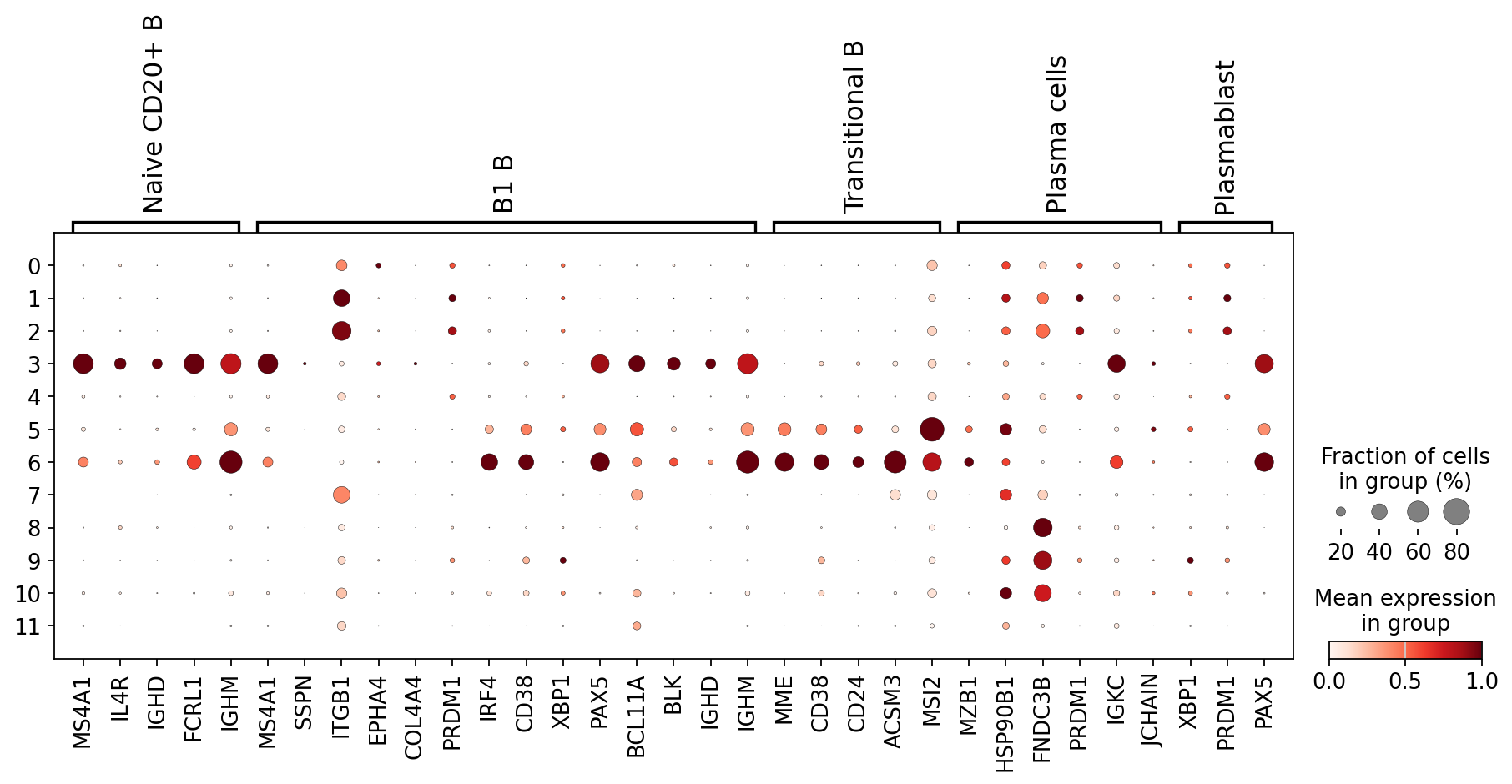
Using a combination of visual inspection of the UMAPs and the dotplot above we can now start annotating the clusters:
cl_annotation = {
"3": "Naive CD20+ B",
"6": "Transitional B",
}
You might notice that the annotation of B1 B cells is difficult, with none of the clusters expressing all the B1 B markers and several clusters expressing some of the markers. We often see that markers that work for one dataset do not work as well for others. This can be due to differences in sequencing depth, but also due to other sources of variation between datasets or samples.
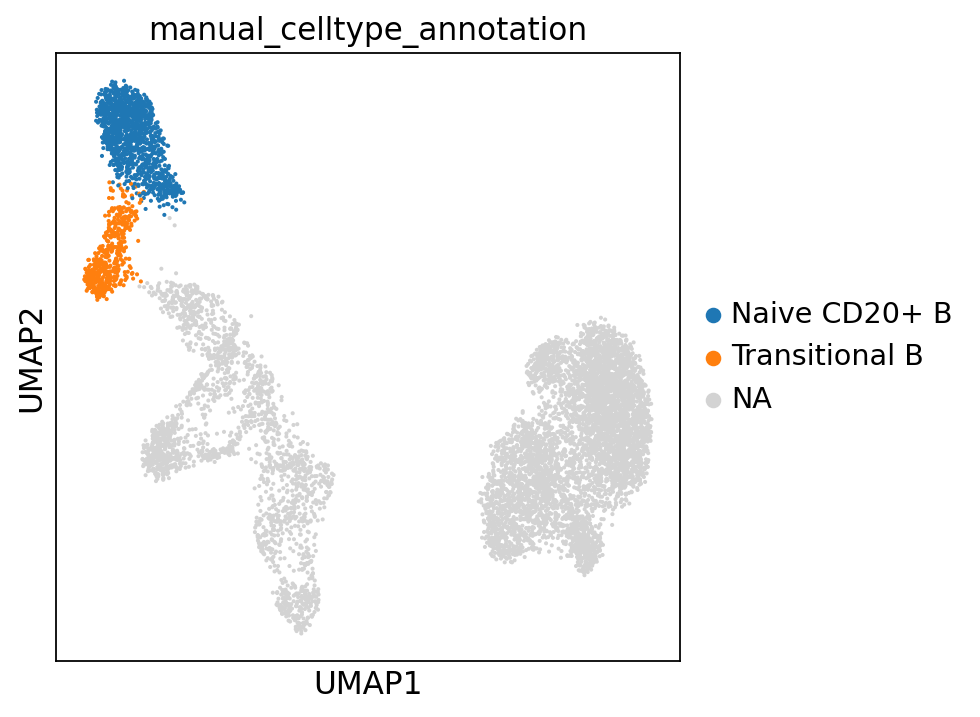
Let’s visualize our annotations so far:
adata.obs["manual_celltype_annotation"] = adata.obs.leiden_1.map(cl_annotation)
sc.pl.umap(adata, color=["manual_celltype_annotation"])
... storing 'manual_celltype_annotation' as categorical
13.4.2. From cluster differentially expressed genes to cluster annotation#
Conversely, we can calculate marker genes per cluster and then look up whether we can link those marker genes to any known biology, such as cell types and/or states. For marker gene calculation of clusters, simple methods such as the Wilcoxon rank-sum test are thought to perform best [Pullin and McCarthy, 2022]. Importantly, as the definition of the clusters is based on the same data as used for these statistical tests, the p-values of these tests will be inflated as also described here [Zhang et al., 2019].
Let’s calculate the differentially expressed genes for every cluster, compared to the rest of the cells in our adata:
sc.tl.rank_genes_groups(
adata, groupby="leiden_1", method="wilcoxon", key_added="dea_leiden_1"
)
We can visualize expression of the top differentially expressed genes per cluster with a standard scanpy dotplot:
sc.tl.dendrogram(
adata,
groupby="leiden_1",
)
sc.pl.rank_genes_groups_dotplot(
adata, groupby="leiden_1", standard_scale="var", n_genes=5, key="dea_leiden_1"
)
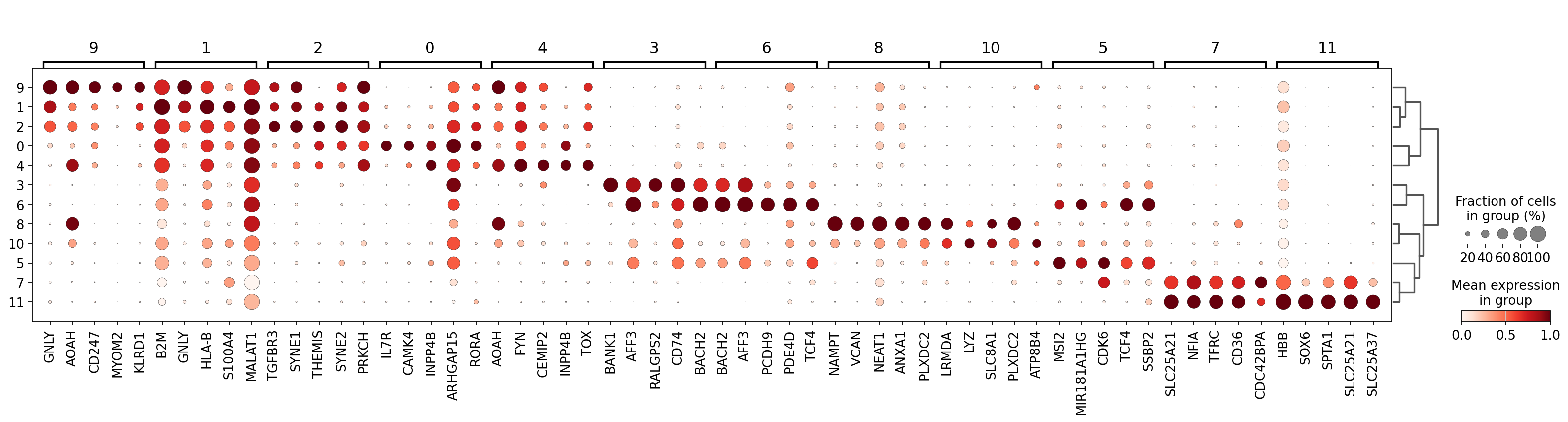
As you can see above, a lot of the differentially expressed genes are highly expressed in multiple clusters. We can filter the differentially expressed genes to select for more cluster-specific differentially expressed genes:
sc.tl.filter_rank_genes_groups(
adata,
min_in_group_fraction=0.2,
max_out_group_fraction=0.2,
key="dea_leiden_1",
key_added="dea_leiden_1_filtered",
)
Visualize the filtered genes :
sc.pl.rank_genes_groups_dotplot(
adata,
groupby="leiden_1",
standard_scale="var",
n_genes=5,
key="dea_leiden_1_filtered",
)
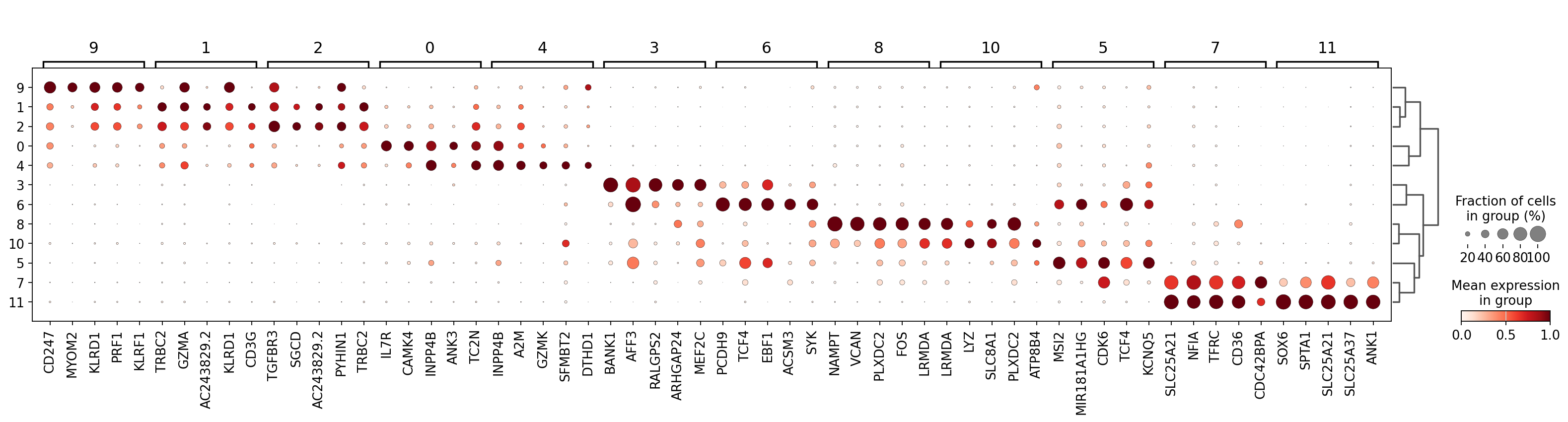
Let’s take a look at cluster 9, which seems to have a set of relatively unique markers including CD247, MOM2, KLRD1, PRF1, and KLRF1. Some googling tells us that e.g. KLRD1 is a marker for NK cells [Isola et al., 2021]. In the UMAP we can see that these genes are expressed throughout cluster 9:
sc.pl.umap(
adata,
color=["CD247", "MYOM2", "KLRD1", "PRF1", "KLRF1", "leiden_1"],
vmax="p99",
legend_loc="on data",
frameon=False,
cmap="Reds",
)
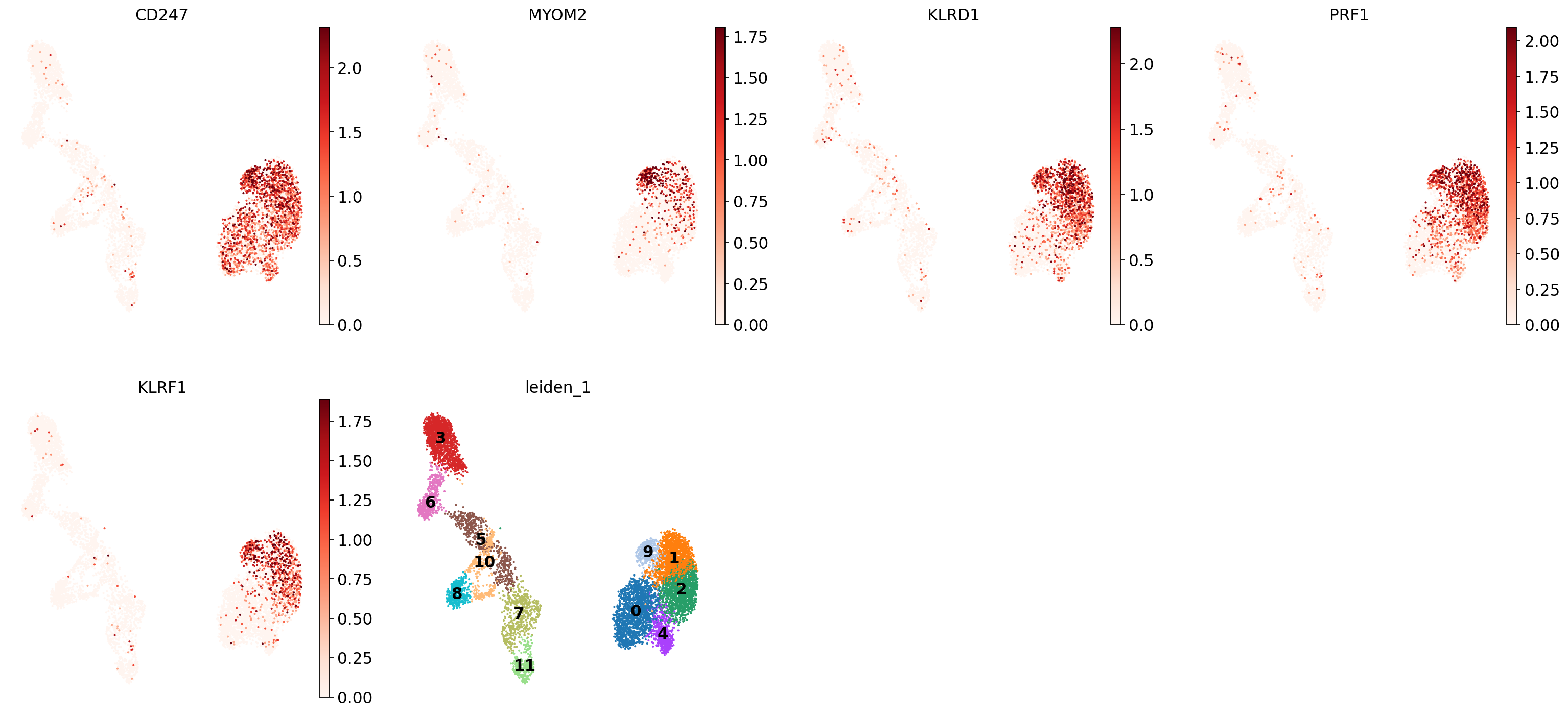
However, marker-based annotation can be sensitive to the cluster resolution you choose, the robustness and uniqueness of the marker sets you have, and your knowledge of the cell types to be expected in your data. Therefore, cluster annotations are not guaranteed to be definitive and should be interpreted with caution.
For this reason, the field is partly trying to move away from manual cluster annotation and rather moving towards automated annotation algorithms instead. The rest of this tutorial will focus on those options.
Before we move on, store the final bit of annotation information in our adata:
cl_annotation["8"] = "NK cells (?)"
adata.obs["manual_celltype_annotation"] = adata.obs.leiden_1.map(cl_annotation)
13.5. Automated annotation#
13.5.1. General remarks#
The remainder of the discussed methods will be methods for automated, rather than manual annotation of your data. Automated approaches are based on different principles, sometimes requiring pre-defined sets of markers, other times trained on pre-existing full scRNA-seq datasets. As discussed below, the resulting annotations can be of varying quality. It is therefore important to regard these methods as a starting point rather than an end-point of the annotation process. See also several reviews [Pasquini et al., 2021], [Abdelaal et al., 2019] for a more elaborate discussion of automated annotation methods.
The quality of automatically generated annotations can vary substantially. More specifically, the quality of the annotations depends on:
The type of classifier chosen: Previous benchmark studies have shown that different types of classifiers often perform comparably, with neural network-based methods generally not outperforming general-purpose models such as support vector machines or linear regression models[Abdelaal et al., 2019], [Pasquini et al., 2021], [Huang and Zhang, 2021].
The quality of the data that the classifier was trained on. If the training data was not well annotated or annotated at low resolution, the classifier will do the same. Similarly, if the training data and/or its annotation was noisy, the classifier might not perform well.
The similarity of your own data to the data that the classifier was trained on. For example, if the classifier was trained on a drop-seq single cell dataset and your data is 10X single nucleus rather than single cell drop-seq, this might worsen the quality of the annotation. Classifiers trained on cross-dataset atlases including a diversity of datasets might give more robust and better quality annotations than classifiers trained on a single dataset. An example is the CellTypist (an automated annotation method that will be discussed more extensively below) classifier trained on the Human Lung Cell Atlas [Sikkema et al., 2023] which includes 14 different lung datasets. This model is likely to perform better on new lung data than a model that was trained on a single lung dataset.
The aforementioned points highlight possible disadvantages of using classifiers, depending on the training data and model type. Nonetheless, there are several important advantages of using pre-trained classifiers to annotate your data. First, it is a fast and easy way to annotate your data. The annotation does not require the downloading nor preprocessing of the training data and sometimes merely involves the upload of your data to an online webpage. Second, these methods don’t rely on a partitioning of your data into clusters, as the manual annotation does. Third, pre-trained classifiers enable you to directly leverage the knowledge and information from previous studies, such as a high quality annotation. And finally, using such classifiers can help with harmonizing cell-type definitions across a field, thereby clearing the path towards a field-wide consensus on these definitions.
Finally, as these classifiers are often less transparent than e.g. manual marker-based annotation, a good uncertainty measure quantifying annotation uncertainty will improve the quality and usability of the method. We will discuss this more extensively further down.
13.5.2. Marker gene-based classifiers#
One class of automated cell type annotation methods relies on a predefined set of marker genes.
Cells are classified into cell types based on their expression levels of these marker genes.
Examples of such methods are Garnett [Pliner et al., 2019] and CellAssign [Zhang et al., 2019].
The more robust and generalizable the set of marker genes these models are based on, the better the model will perform.
However, like with other models they are likely to be affected by batch effect-related differences between the data the model was trained on and the data that needs to be labeled.
One of the advantages of these methods compared to models based on larger gene sets (see below) is that they are more transparent: we know on the basis of which genes the classification is done.
We will not show an example of marker-based classifiers in this notebook, but encourage you to explore these yourself if you are interested.
13.5.3. Classifiers based on a wider set of genes#
It is worth noting that the methods discussed so far use only a small subset of the genes detected in the data: often a set of only 1 to ~10 marker genes per cell type is used. An alternative approach is to use a classifier that takes as input a larger set of genes (several thousands or more), thereby making more use of the breadth of scRNA-seq data. Such classifiers are trained on previously annotated datasets or atlases. Examples of these are CellTypist [Conde et al., 2022] (see also https://www.celltypist.org, where data can be uploaded to a portal to get automated cell annotations) and Clustifyr [Fu et al., 2020].
Let’s try out CellTypist on our data. Based on the CellTypist tutorial (https://www.celltypist.org/tutorials) we know we need to prepare our data so that counts are normalized to 10,000 counts per cell, then log1p-transformed:
adata_celltypist = adata.copy() # make a copy of our adata
adata_celltypist.X = adata.layers["counts"] # set adata.X to raw counts
sc.pp.normalize_total(
adata_celltypist, target_sum=10**4
) # normalize to 10,000 counts per cell
sc.pp.log1p(adata_celltypist) # log-transform
# make .X dense instead of sparse, for compatibility with celltypist:
adata_celltypist.X = adata_celltypist.X.toarray()
We’ll now download the celltypist models for immune cells:
models.download_models(
force_update=True, model=["Immune_All_Low.pkl", "Immune_All_High.pkl"]
)
Let’s try out both the Immune_All_Low and Immune_All_High models (these annotate immune cell types finer annotation level (low) and coarser (high)):
model_low = models.Model.load(model="Immune_All_Low.pkl")
model_high = models.Model.load(model="Immune_All_High.pkl")
For each of these, we can see which cell types it includes to see if bone marrow cell types are included:
model_high.cell_types
array(['B cells', 'B-cell lineage', 'Cycling cells', 'DC', 'DC precursor',
'Double-negative thymocytes', 'Double-positive thymocytes', 'ETP',
'Early MK', 'Endothelial cells', 'Epithelial cells',
'Erythrocytes', 'Erythroid', 'Fibroblasts', 'Granulocytes',
'HSC/MPP', 'ILC', 'ILC precursor', 'MNP', 'Macrophages',
'Mast cells', 'Megakaryocyte precursor',
'Megakaryocytes/platelets', 'Mono-mac', 'Monocyte precursor',
'Monocytes', 'Myelocytes', 'Plasma cells', 'Promyelocytes',
'T cells', 'pDC', 'pDC precursor'], dtype=object)
model_low.cell_types
array(['Age-associated B cells', 'Alveolar macrophages', 'B cells',
'CD16+ NK cells', 'CD16- NK cells', 'CD8a/a', 'CD8a/b(entry)',
'CMP', 'CRTAM+ gamma-delta T cells', 'Classical monocytes',
'Cycling B cells', 'Cycling DCs', 'Cycling NK cells',
'Cycling T cells', 'Cycling gamma-delta T cells',
'Cycling monocytes', 'DC', 'DC precursor', 'DC1', 'DC2', 'DC3',
'Double-negative thymocytes', 'Double-positive thymocytes', 'ELP',
'ETP', 'Early MK', 'Early erythroid', 'Early lymphoid/T lymphoid',
'Endothelial cells', 'Epithelial cells', 'Erythrocytes',
'Erythrophagocytic macrophages', 'Fibroblasts',
'Follicular B cells', 'Follicular helper T cells', 'GMP',
'Germinal center B cells', 'Granulocytes', 'HSC/MPP',
'Hofbauer cells', 'ILC', 'ILC precursor', 'ILC1', 'ILC2', 'ILC3',
'Intermediate macrophages', 'Intestinal macrophages',
'Kidney-resident macrophages', 'Kupffer cells',
'Large pre-B cells', 'Late erythroid', 'MAIT cells', 'MEMP', 'MNP',
'Macrophages', 'Mast cells', 'Megakaryocyte precursor',
'Megakaryocyte-erythroid-mast cell progenitor',
'Megakaryocytes/platelets', 'Memory B cells',
'Memory CD4+ cytotoxic T cells', 'Mid erythroid', 'Migratory DCs',
'Mono-mac', 'Monocyte precursor', 'Monocytes', 'Myelocytes',
'NK cells', 'NKT cells', 'Naive B cells',
'Neutrophil-myeloid progenitor', 'Neutrophils',
'Non-classical monocytes', 'Plasma cells', 'Plasmablasts',
'Pre-pro-B cells', 'Pro-B cells',
'Proliferative germinal center B cells', 'Promyelocytes',
'Regulatory T cells', 'Small pre-B cells', 'T(agonist)',
'Tcm/Naive cytotoxic T cells', 'Tcm/Naive helper T cells',
'Tem/Effector helper T cells', 'Tem/Effector helper T cells PD1+',
'Tem/Temra cytotoxic T cells', 'Tem/Trm cytotoxic T cells',
'Transitional B cells', 'Transitional DC', 'Transitional NK',
'Treg(diff)', 'Trm cytotoxic T cells', 'Type 1 helper T cells',
'Type 17 helper T cells', 'gamma-delta T cells', 'pDC',
'pDC precursor'], dtype=object)
Looks like the models include many different immune cell type progenitors!
Now let’s run the models. First the coarse one:
predictions_high = celltypist.annotate(
adata_celltypist, model=model_high, majority_voting=True
)
🔬 Input data has 8874 cells and 12850 genes
🔗 Matching reference genes in the model
🧬 4237 features used for prediction
⚖️ Scaling input data
🖋️ Predicting labels
✅ Prediction done!
👀 Detected a neighborhood graph in the input object, will run over-clustering on the basis of it
⛓️ Over-clustering input data with resolution set to 10
🗳️ Majority voting the predictions
✅ Majority voting done!
Transform the predictions to adata to get the full output…
predictions_high_adata = predictions_high.to_adata()
…and copy the results to our original AnnData object:
adata.obs["celltypist_cell_label_coarse"] = predictions_high_adata.obs.loc[
adata.obs.index, "majority_voting"
]
adata.obs["celltypist_conf_score_coarse"] = predictions_high_adata.obs.loc[
adata.obs.index, "conf_score"
]
Now the same for the finer annotations:
predictions_low = celltypist.annotate(
adata_celltypist, model=model_low, majority_voting=True
)
🔬 Input data has 8874 cells and 12850 genes
🔗 Matching reference genes in the model
🧬 4237 features used for prediction
⚖️ Scaling input data
🖋️ Predicting labels
✅ Prediction done!
👀 Detected a neighborhood graph in the input object, will run over-clustering on the basis of it
⛓️ Over-clustering input data with resolution set to 10
🗳️ Majority voting the predictions
✅ Majority voting done!
predictions_low_adata = predictions_low.to_adata()
adata.obs["celltypist_cell_label_fine"] = predictions_low_adata.obs.loc[
adata.obs.index, "majority_voting"
]
adata.obs["celltypist_conf_score_fine"] = predictions_low_adata.obs.loc[
adata.obs.index, "conf_score"
]
Now plot:
sc.pl.umap(
adata,
color=["celltypist_cell_label_coarse", "celltypist_conf_score_coarse"],
frameon=False,
sort_order=False,
wspace=1,
)
... storing 'manual_celltype_annotation' as categorical

sc.pl.umap(
adata,
color=["celltypist_cell_label_fine", "celltypist_conf_score_fine"],
frameon=False,
sort_order=False,
wspace=1,
)

One way of getting a feeling for the quality of these annotations is by looking if the observed cell type similarities correspond to our expectations:
sc.tl.dendrogram(
adata,
groupby="celltypist_cell_label_fine",
)
sc.pl.dendrogram(adata, groupby="celltypist_cell_label_fine")
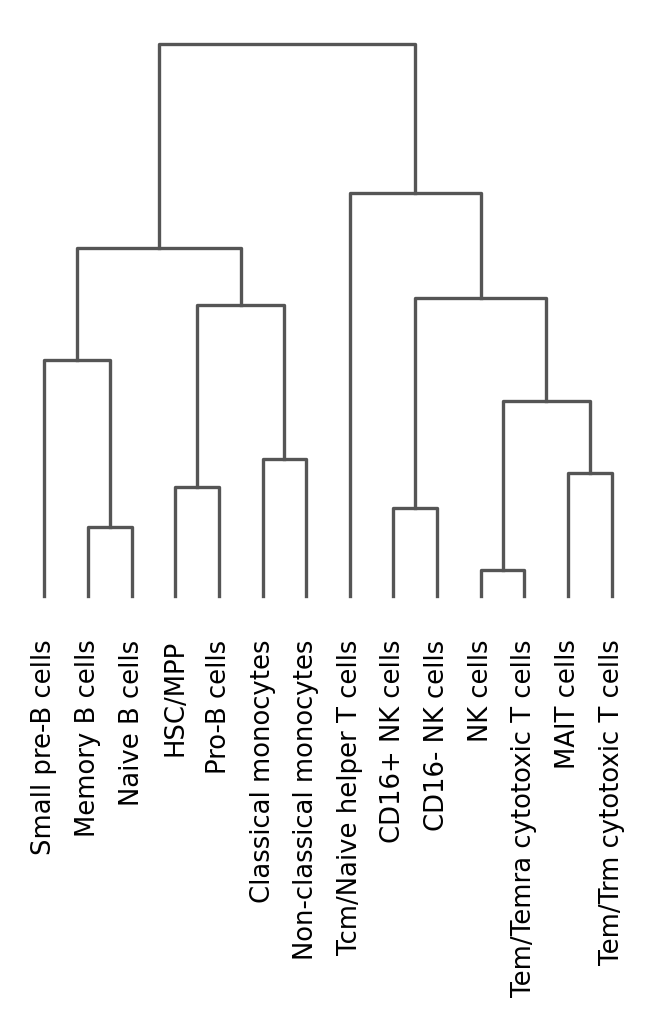
<Axes: >
This dendrogram shows us that the cells are well clustered with each other (e.g., B cells largely clustering together). It is very important to check the automated annotation manually before simply taking them!
Cross-checking automated annotations with manual annotations
Dendrograms often reveal unexpected patterns, such as a specific B cell subtype failing to cluster with other B cells. This discrepancy often suggests inaccurate automated labeling.
To diagnose these cases:
Validate the clusters using alternative annotation sources or known marker genes.
Check confidence scores of the automated annotations. Low scores in “misplaced” clusters are a strong signal that manual intervention is required.
You can also take a look at the breakdown of a specific cluster to investigate:
pd.crosstab(adata.obs.leiden_1, adata.obs.celltypist_cell_label_fine).loc[
"8", :
].sort_values(ascending=False)
Automated annotations may only partially correspond to manual labels and can even be inconsistent between their own coarse and fine classifications.
This underlines that automated annotation algorithms should be used with caution and should be regarded as a starting point for annotating your data, rather than as a final annotation. Ultimately, expression of known marker genes is still the most accepted support for a cell type annotation.
13.5.4. Annotation by mapping to a reference#
A final way to annotate your data is based on mapping your data to an existing, annotated single-cell reference and then performing label transfer using the resulting joint embedding. This reference can for example be a single sample that you annotated manually before, after which you would like to transfer those annotations to the rest of your dataset. Alternatively, it can be a published and ideally well-curated existing reference. In this context we refer to the “new data”, i.e. the data to be mapped and annotated, as the “query”.
There are multiple existing methods that perform such “query-to-reference mapping”, including scArches [Lotfollahi et al., 2022], Symphony [Kang et al., 2021], and Azimuth (Seurat) [Hao et al., 2021]. All of these methods enable you to map a new dataset to an existing reference without needing to reintegrate the data from the reference and without needing access to the full reference data.
As query-to-reference mapping involves embedding new data into an existing low-dimensional representation of the reference data, the dimensions and axes of that low-dimensional representation are largely pre-defined before learning from the query. Therefore, learning and incorporating unseen variation that might be present in the query (both new biological variation, e.g. unseen cell types or states and new technical variation, i.e. unseen batch effects that need to be removed) can be a challenge for these models. As a result, integration of the query data with the reference might not always be optimal and batch effects might not be fully removed from the joint query-reference embedding. However, as cell type label transfer does not necessarily require perfect integration but merely close proximity of identical cell types in the embedding, even an imperfect mapping can still be extremely helpful in annotating your data.
scArches, which we will use as an example of reference-mapping-based label transfer, takes as its basis an existing (variational autoencoder-based) model that embeds the reference data in a low-dimensional, batch-corrected space. It then slightly extends that model to enable the mapping of an unseen dataset into the same “latent space” (i.e. the low-dimensional embedding). This model extension also enables the learning and removal of batch effects present in the mapped dataset.
We will now show how to map data to a reference using scArches and use this mapping to perform label transfer from the reference to the new data (“query”).
Warning
Note that scArches does not run, or runs very slowly if you do not have access to a GPU. You might therefore need to run this part of the notebook from a computing cluster/server.
Let’s start by preparing our data for the mapping to a reference. scArches, the method that enables us to adapt an existing reference model to new data requires raw, non-normalized counts. We will therefore keep our counts layer and remove all other layers from our adata to map. We will set our .X to those raw counts as well.
adata_to_map = adata.copy()
for layer in list(adata_to_map.layers.keys()):
if layer != "counts":
del adata_to_map.layers[layer]
adata_to_map.X = adata_to_map.layers["counts"]
Moreover, it is important that we use the same input features (i.e. genes) as were used for training our reference model and that we put those features in the same order. The reference model’s feature information is stored together with the model. Let’s load the feature table.
af = ln.Artifact.connect("theislab/sc-best-practices").get(
key="cellular_structure/annotation_reference_features.csv", is_latest=True
)
reference_model_features = af.load()
... synchronizing annotation_reference_features.csv: 100.0%
The table has both gene names and gene IDs.
As gene IDs are usually less subject to change over genome annotation versions, we will use those to subset our data.
We will therefore set our row names for both our adata and the reference model features to gene_ids.
Importantly, we have to make sure to also store the gene names for later use: these are much easier to understand than the gene IDs.
adata_to_map.var["gene_names"] = adata_to_map.var.index
adata_to_map.var.set_index("gene_id", inplace=True)
reference_model_features["gene_names"] = reference_model_features.index
reference_model_features.set_index("gene_ids", inplace=True)
Now, let’s check if we have all the genes we need in our query data:
print("Total number of genes needed for mapping:", reference_model_features.shape[0])
Total number of genes needed for mapping: 4000
print(
"Number of genes found in query dataset:",
adata_to_map.var.index.isin(reference_model_features.index).sum(),
)
Number of genes found in query dataset: 2725
We are missing some genes. We will manually add those and set their counts to 0, as it seems like these genes were not detected in our data. Let’s create an AnnData object for those missing genes with only zero values (including our raw counts layer, which will be used for the mapping). We will concatenate that to our own AnnData objects afterwards.
missing_genes = [
gene_id
for gene_id in reference_model_features.index
if gene_id not in adata_to_map.var.index
]
missing_gene_adata = sc.AnnData(
X=csr_matrix(np.zeros(shape=(adata.n_obs, len(missing_genes))), dtype="float32"),
obs=adata.obs.iloc[:, :1],
var=reference_model_features.loc[missing_genes, :],
)
missing_gene_adata.layers["counts"] = missing_gene_adata.X
Concatenate our original adata to the missing genes adata. To make sure we can do this concatenation without errors, we’ll remove the PCA matrix from varm.
if "PCs" in adata_to_map.varm.keys():
del adata_to_map.varm["PCs"]
adata_to_map_augmented = sc.concat(
[adata_to_map, missing_gene_adata],
axis=1,
join="outer",
index_unique=None,
merge="unique",
)
Now subset to the genes used in the model and order correctly:
adata_to_map_augmented = adata_to_map_augmented[
:, reference_model_features.index
].copy()
Check if our adata gene names correspond exactly to the required gene order:
bool((adata_to_map_augmented.var.index == reference_model_features.index).all())
True
We can now set the gene indices back to gene names for easy interpretation:
adata_to_map_augmented.var["gene_ids"] = adata_to_map_augmented.var.index
adata_to_map_augmented.var.set_index("gene_names", inplace=True)
Finally, this reference model used adata.obs['batch'] as our batch variable.
We will therefore check that we have this set to one value for our entire sample:
adata_to_map_augmented.obs.batch.unique()
['s4d8']
Categories (1, object): ['s4d8']
Now let’s talk about our reference model. The better our reference model, the better our label transfer will perform. Using well-annotated reference that integrates many different datasets and that matches your data well (same organ, same single-cell technology etc.) is ideal: such models are trained on a variety of datasets and batches and are therefore expected to be more robust to batch effects. However, such references do not exist yet for all tissues. For this tutorial we will use a reference model trained on the bone marrow samples that we have been using throughout the book, excluding the sample that we will be mapping. The reference model is an scvi-model (used for data integration) that generates a low-dimensional, integrated embedding of the input data, see also the scvi-publication [Lopez et al., 2018]. Note that this is a toy model generated for this tutorial and it should not be used in other contexts.
We will start by patching things up for compatibility, because this model was built on previous version of pandas.
sys.modules["pandas.core.indexes.numeric"] = pandas_indexes_base
pandas_indexes_base.Int64Index = pd.Index
pandas_indexes_base.Float64Index = pd.Index
Now, let’s load the model and pass it the adata which we want to map.
af = ln.Artifact.connect("theislab/sc-best-practices").get(
key="cellular_structure/annotation_reference_model.pt", is_latest=True
)
annotation_ref_model_path = af.cache()
model_dir = Path("./reference_model")
model_dir.mkdir(parents=True, exist_ok=True)
shutil.copy(annotation_ref_model_path, model_dir / "model.pt")
... synchronizing annotation_reference_model.pt: 100.0%
PosixPath('reference_model/model.pt')
scarches_model = sca.models.SCVI.load_query_data(
adata=adata_to_map_augmented,
reference_model=str(model_dir),
freeze_dropout=True,
)
INFO File reference_model/model.pt already downloaded
We will now update this reference model so that we can embed our own data (the “query”) in the same latent space as the reference. This requires training on our query data using scArches:
scarches_model.train(max_epochs=500, plan_kwargs={"weight_decay": 0.0})
INFO: GPU available: False, used: False
GPU available: False, used: False
INFO: TPU available: False, using: 0 TPU cores
TPU available: False, using: 0 TPU cores
INFO: 💡 Tip: For seamless cloud logging and experiment tracking, try installing [litlogger](https://pypi.org/project/litlogger/) to enable LitLogger, which logs metrics and artifacts automatically to the Lightning Experiments platform.
💡 Tip: For seamless cloud logging and experiment tracking, try installing [litlogger](https://pypi.org/project/litlogger/) to enable LitLogger, which logs metrics and artifacts automatically to the Lightning Experiments platform.
Epoch 500/500: 100%|██████████| 500/500 [54:55<00:00, 4.48s/it, v_num=1, train_loss_step=961, train_loss_epoch=1e+3]
INFO: `Trainer.fit` stopped: `max_epochs=500` reached.
`Trainer.fit` stopped: `max_epochs=500` reached.
Epoch 500/500: 100%|██████████| 500/500 [54:55<00:00, 6.59s/it, v_num=1, train_loss_step=961, train_loss_epoch=1e+3]
Now that we have updated the model, we can calculate the (ideally batch-corrected) latent representation of our query:
adata.obsm["X_scVI"] = scarches_model.get_latent_representation()
We can now use this newly calculated low-dimensional embedding as a basis for visualization and clustering. Let’s calculate the new UMAP using the scVI-based representation of the data.
sc.pp.neighbors(adata, use_rep="X_scVI")
sc.tl.umap(adata)
To see if the mapping-based UMAP makes general sense, let’s look at a few markers and if their expression is localized to specific parts of the UMAP:
sc.pl.umap(
adata,
color=["IGHD", "IGHM", "PRDM1"],
vmin=0,
vmax="p99", # set vmax to the 99th percentile of the gene count instead of the maximum, to prevent outliers from making expression in other cells invisible. Note that this can cause problems for extremely lowly expressed genes.
sort_order=False, # do not plot highest expression on top, to not get a biased view of the mean expression among cells
frameon=False,
cmap="Reds", # or choose another color map e.g. from here: https://matplotlib.org/stable/tutorials/colors/colormaps.html
)
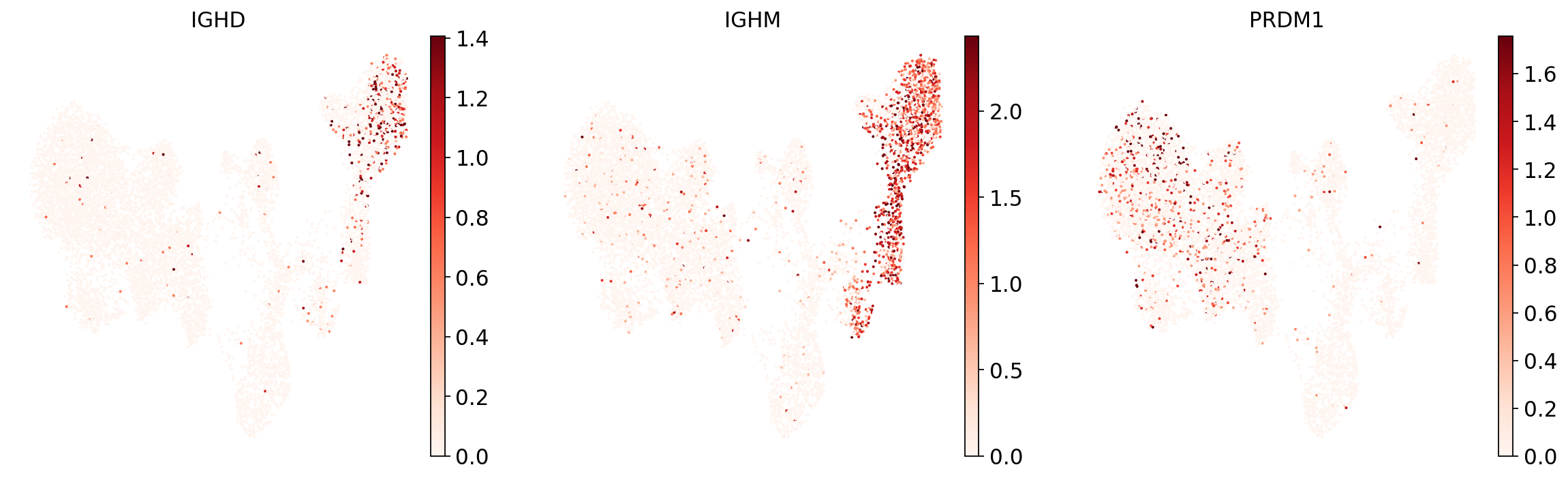
Now the essential step is that we can combine the inferred latent space embedding of our query data with the existing reference embedding. Using this joint embedding, we will not only be able to e.g., visualize and cluster the two together, but we can also do label transfer from the query to the reference.
Let’s load the reference embedding: this is often made publicly available with existing atlases.
af = ln.Artifact.get(
key="cellular_structure/annotation_reference_embedding.h5ad", is_latest=True
)
ref_emb = af.load(is_run_input=False)
... synchronizing annotation_reference_embedding.h5ad: 100.0%
We’ll store a variable specifying that these cells are from the reference.
ref_emb.obs["reference_or_query"] = "reference"
Let’s see what’s in this reference object:
ref_emb
AnnData object with n_obs × n_vars = 86332 × 10
obs: 'donor', 'batch', 'site', 'cell_type', 'reference_or_query'
uns: 'neighbors', 'umap'
obsm: 'X_umap'
obsp: 'connectivities', 'distances'
As you can see it has only 10 dimensions (in .X) which together represent the latent space embedding of the reference cells.
Our query embedding that we calculated for our own data also has 10 dimensions.
The 10 dimensions of the reference and query are the same and can be combined!
Moreover, it has cell type labels in .obs['cell_type'].
We will use these labels to annotate our own data.
To perform the label transfer, we will first concatenate the reference and query data using the 10-dimensional embedding.
To get there, we will create the same type of AnnData object from our query data as we have from the reference (with the embedding under .X) and concatenate the two.
With that, we can jointly analyze reference and query including doing transfer from one to the other.
adata_emb = sc.AnnData(X=adata.obsm["X_scVI"], obs=adata.obs)
adata_emb.obs["reference_or_query"] = "query"
We will set the cell type labels in .obs["cell_type"] as None, so that we can see how we can annotate cell types based on the surroundings.
adata_emb.obs["cell_type"] = None
emb_ref_query = sc.concat(
[ref_emb, adata_emb],
axis=0,
join="outer",
index_unique=None,
merge="unique",
)
Let’s visualize the joint embedding with a UMAP.
sc.pp.neighbors(emb_ref_query)
sc.tl.umap(emb_ref_query)
We can visually get a first impression of whether the reference and query integrated well based on the UMAP:
sc.pl.umap(
emb_ref_query,
color=["reference_or_query"],
sort_order=False,
frameon=False,
)
... storing 'reference_or_query' as categorical

The (partial) mixing of query and reference in this UMAP is a good sign! When mapping completely fails, you will often see a full separation of query and reference in the UMAP.
Now let’s look at the cell type annotations from the reference. All cells from the query are set to NA here as they don’t have annotations yet and shown in black.
We’ll make this figure a bit bigger so that we can read the legend well:
sc.set_figure_params(figsize=(8, 8))
sc.pl.umap(
emb_ref_query,
color=["cell_type"],
sort_order=False,
frameon=False,
legend_loc="on data",
legend_fontsize=10,
na_color="black",
)
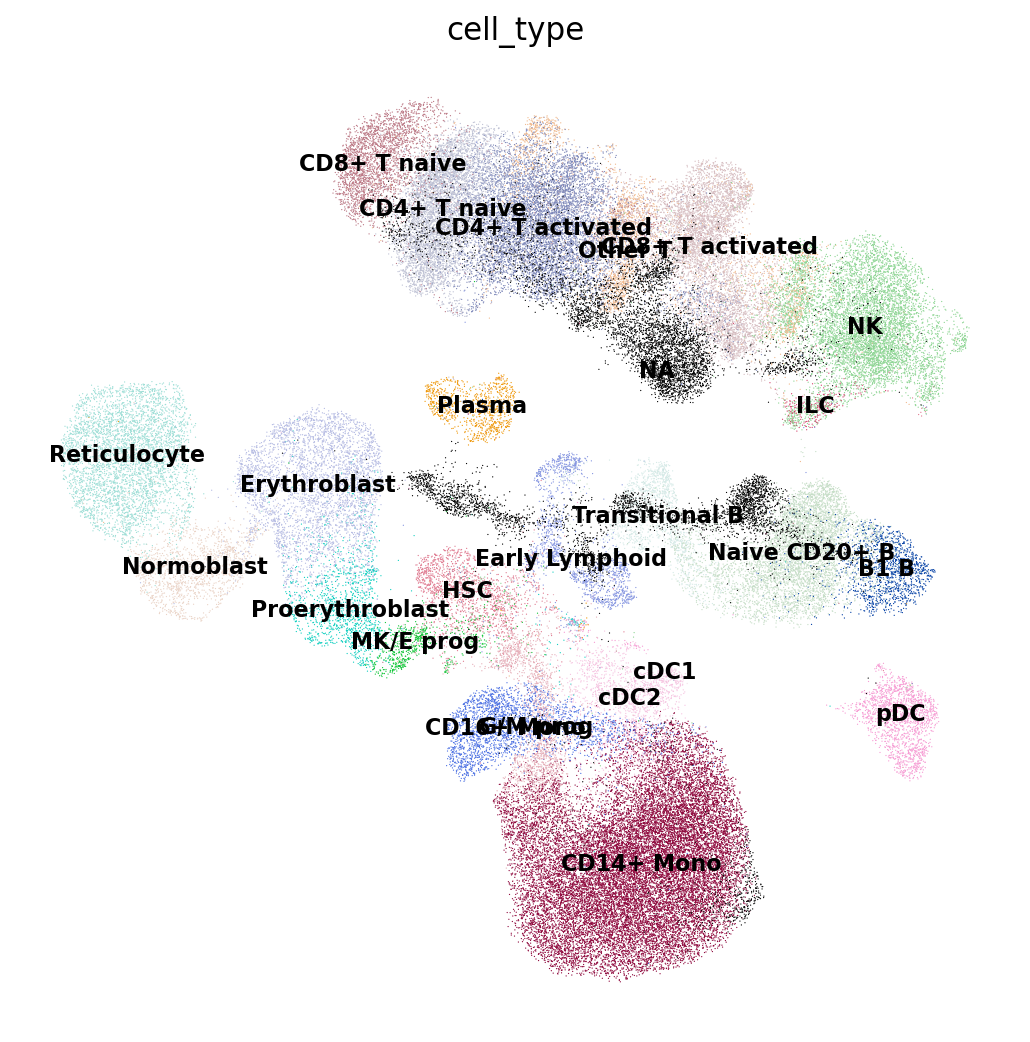
As you can already tell from the UMAP, we can guess the cell type of each of our own cells (in black) by looking at which cell types from the reference surrounding it. This is exactly what a nearest-neighbor-graph-based label transfer approach does: for each query cell it checks what is the most common cell type among its neighboring reference cells. The higher the fraction of reference cells coming from a single cell type, the more confident the label transfer is.
Let’s perform the KNN-based label transfer.
First we set up the label transfer model:
knn_transformer = sca.utils.knn.weighted_knn_trainer(
train_adata=ref_emb,
train_adata_emb="X", # location of our joint embedding
n_neighbors=15,
)
Weighted KNN with n_neighbors = 15 ...
Now we perform the label transfer:
labels, uncert = sca.utils.knn.weighted_knn_transfer(
query_adata=adata_emb,
query_adata_emb="X", # location of our embedding, query_adata.X in this case
label_keys="cell_type", # (start of) obs column name(s) for which to transfer labels
knn_model=knn_transformer,
ref_adata_obs=ref_emb.obs,
)
finished!
And store the results in our adata:
adata_emb.obs["transf_cell_type"] = labels.loc[adata_emb.obs.index, "cell_type"]
adata_emb.obs["transf_cell_type_unc"] = uncert.loc[adata_emb.obs.index, "cell_type"]
Let’s transfer the results to our query adata object which also has our UMAP and gene counts, so that we can visualize all of those together.
adata.obs.loc[adata_emb.obs.index, "transf_cell_type"] = adata_emb.obs[
"transf_cell_type"
]
adata.obs.loc[adata_emb.obs.index, "transf_cell_type_unc"] = adata_emb.obs[
"transf_cell_type_unc"
]
adata.obs["transf_cell_type_unc"] = adata.obs["transf_cell_type_unc"].astype(
float
) # ensure uncertainty is float, for compatibility with downstream plotting functions
We can now visualize the transferred labels in our previously calculated UMAP of our own data:
Let’s set the figure size smaller again:
sc.set_figure_params(figsize=(5, 5))
sc.pl.umap(adata, color="transf_cell_type", frameon=False)
... storing 'transf_cell_type' as categorical
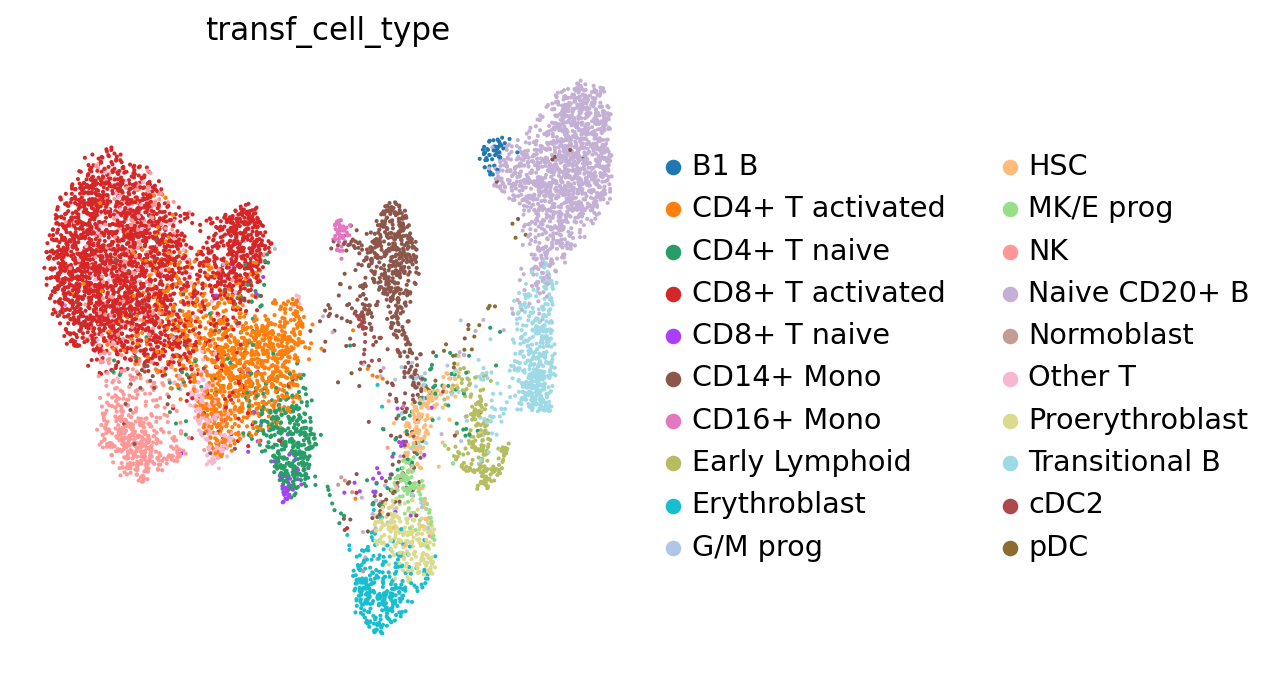
Based on the neighbors of each of our query cells we can not only guess the cell type these cells belong to, but also generate a measure for certainty of that label: if a cell has neighbors from several different cell types, our guess will be highly uncertain. This is relevant to assess to what extent we can “trust” the transferred labels! Let’s visualize the uncertainty scores:
sc.pl.umap(adata, color="transf_cell_type_unc", frameon=False)
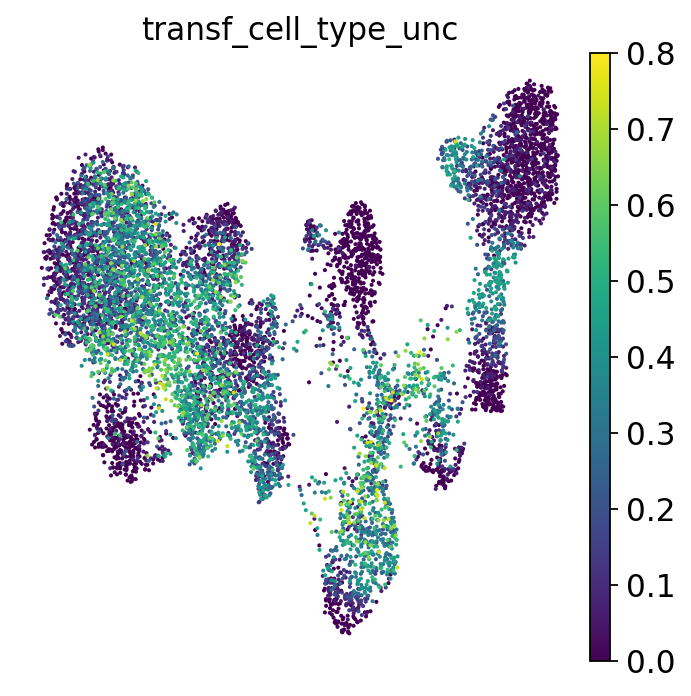
Let’s check for each cell type label how high the label transfer uncertainty levels were. This gives us a first impression of which annotations are more contentious/need more manual checks.
fig, ax = plt.subplots(figsize=(8, 3))
ct_order = (
adata.obs.groupby("transf_cell_type")
.agg({"transf_cell_type_unc": "median"})
.sort_values(by="transf_cell_type_unc", ascending=False)
)
sns.boxplot(
adata.obs,
x="transf_cell_type",
y="transf_cell_type_unc",
color="grey",
ax=ax,
order=ct_order.index,
)
ax.tick_params(rotation=90, axis="x")
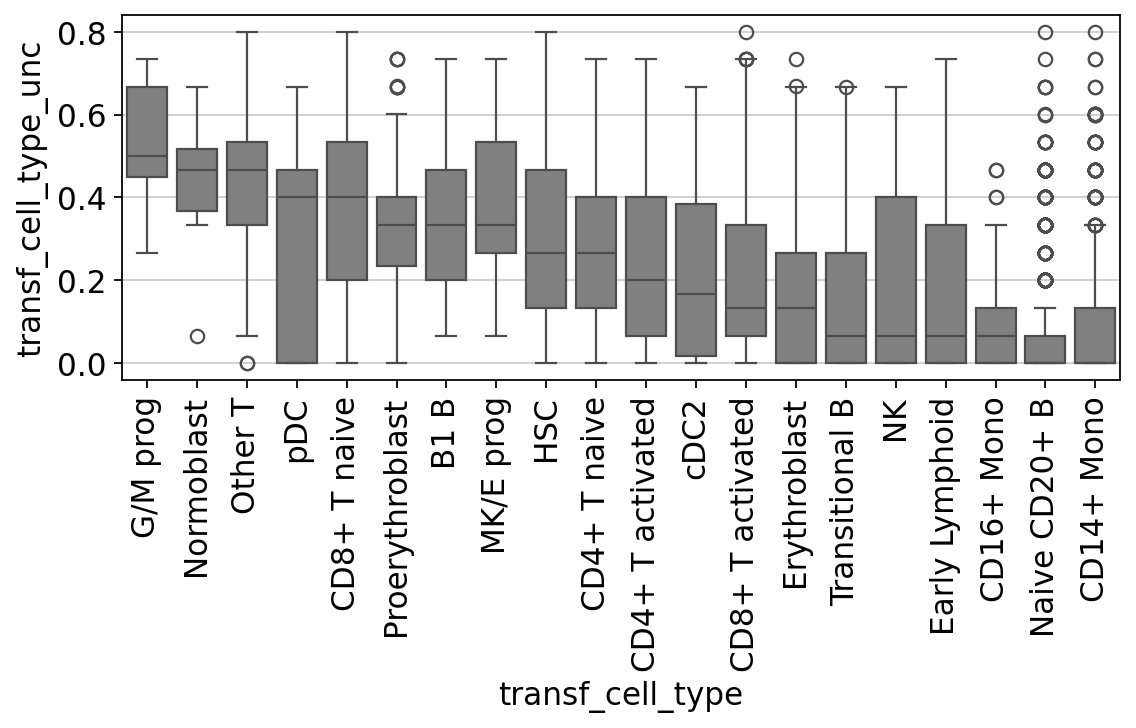
You’ll notice that e.g. progenitor cells are often more difficult to distinguish than other cell types. Same for the rather unspecific category “Other T” cells in our annotations. We can see that pDC, a cell type that is known to be quite transcriptionally distinct and therefore easier to recognize and label, spreads from 0.0 to 0.5.
To incorporate this uncertainty information in our transferred labels, we can set cells with an uncertainty score above e.g. 0.2 to “unknown”:
adata.obs["transf_cell_type_certain"] = adata.obs.transf_cell_type.tolist()
adata.obs.loc[adata.obs.transf_cell_type_unc > 0.2, "transf_cell_type_certain"] = (
"Unknown"
)
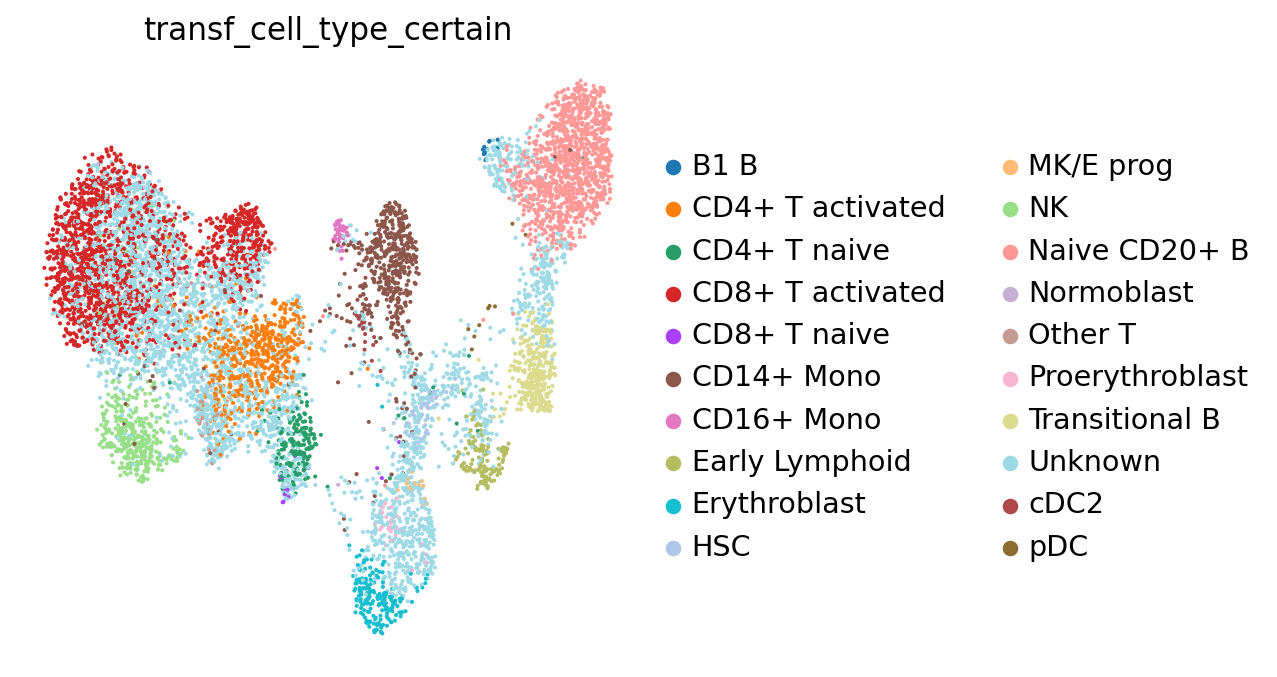
Let’s see what our annotations look like after this filtering. Note the Unknown color in the legend and the UMAP.
sc.pl.umap(adata, color="transf_cell_type_certain", frameon=False)
... storing 'transf_cell_type_certain' as categorical
To ease legibility, we can color only the “unknown” cells. This will make it easier for us to see how many of those there are. You can do the same with any of the other cell type labels.
sc.pl.umap(adata, color="transf_cell_type_certain", groups="Unknown")

There are quite many of them! These cells will need particularly careful manual reviewing. However, the low-uncertainty annotations surrounding the “unknown cells” will already give us a first idea of what cell type we can expect each cell to belong to.
Now let’s take a look at our more certain annotations. We will check for a few cell types (chosen at random here) to what extent the reference-transferred annotation matches our known marker genes from above. In reality, this should be done systematically for all annotations!
cell_types_to_check = [
"CD14+ Mono",
"cDC2",
"NK",
"B1 B",
"CD4+ T activated",
"T naive",
"MK/E prog",
]
Conveniently, for each of these cell types we have markers in our dictionary. Let’s plot marker expression for all our newly annotated cell types. You will notice that marker expression generally corresponds to the automated annotations, a good sign!
sc.pl.dotplot(
adata,
var_names={
ct: marker_genes_in_data[ct] for ct in cell_types_to_check
}, # gene names grouped by cell type in a dictionary
groupby="transf_cell_type_certain",
standard_scale="var", # normalize gene scores from 0 to 1
)
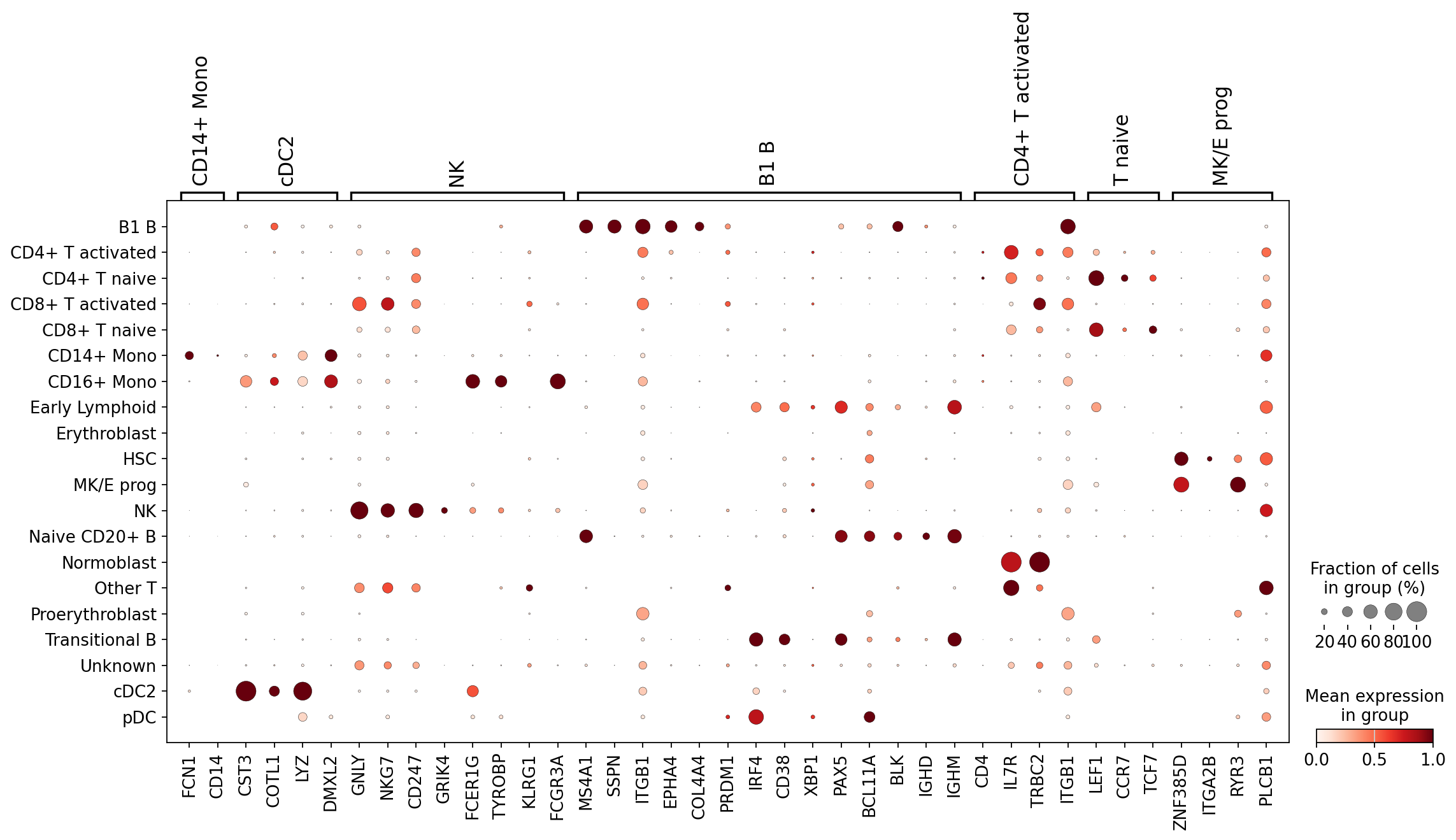
As you can see, the marker groups are generally most highly expressed in the cells annotated with the matching label. This means these labels are likely (at least partially) correct!
Let’s go back one more time to our UMAP colored by uncertainty:
sc.pl.umap(
adata, color=["transf_cell_type_unc", "transf_cell_type_certain"], frameon=False
)
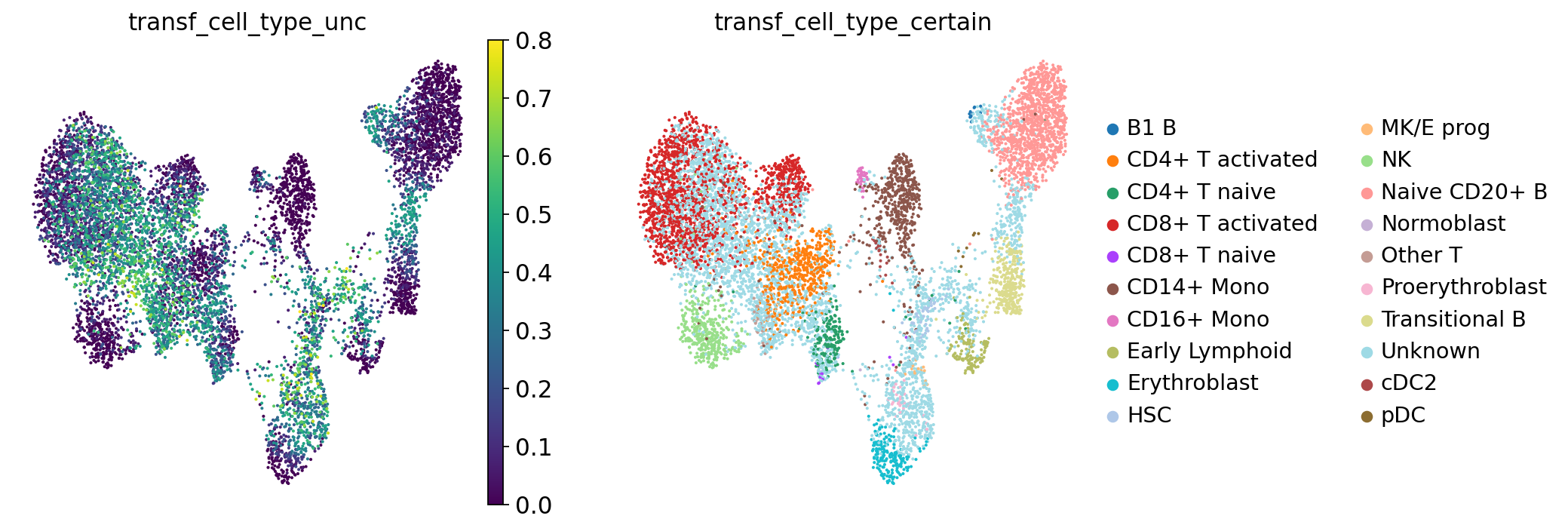
The uncertainty not only helps us identify regions where the algorithm is unsure which cell type a cell belongs to (e.g., because it falls between two annotated phenotypes), but can also highlight unseen cell types or new cell states. For example, your reference might consist of healthy cells while your query could be from a diseased sample. The uncertainty score can then highlight disease-specific cell states, as they might not have neighbors from the reference that consistently come from a single cell type. Especially when your reference is based on a large dataset, the uncertainty score is useful for flagging parts of the query data that could be worth investigating. Reference-based label transfer not only helps you annotate your data but can also speed up its exploration and interpretation. However, as with any metric, these uncertainty scores are often imperfect and, in some cases, fail to highlight new cell types or states. For a more extensive discussion of uncertainty metrics, see e.g. [Engelmann et al., 2022].
Like with any of the methods discussed in this notebook, the quality of the transferred annotations depends on the quality of the “training data” (in this case the reference) and its annotations, the quality of the model, and the match of your own data with the training data!
The quality of the transferred annotations should therefore always be validated with manual inspection using marker gene expression and refinement of the initial annotations might be needed.
# formatting the 'names' column as string, to prevent problems with saving to h5ad format
fields = adata.uns["dea_leiden_1_filtered"]["names"].dtype.names
for field in fields:
adata.uns["dea_leiden_1_filtered"]["names"][field] = adata.uns[
"dea_leiden_1_filtered"
]["names"][field].astype(str)
af = ln.Artifact.from_anndata(
adata,
key="cellular_structure/s4d8_annotated.h5ad",
description="anndata after annotation",
).save()
af
→ creating new artifact version for key 'cellular_structure/s4d8_annotated.h5ad' in storage 's3://lamin-eu-central-1/VPwcjx3CDAa2'
... uploading 7d6LdOoS4ZSxqQPw0001.h5ad: 100.0%
Artifact(uid='7d6LdOoS4ZSxqQPw0001', key='cellular_structure/s4d8_annotated.h5ad', description='anndata after annotation', suffix='.h5ad', kind='dataset', otype='AnnData', size=394355944, hash='EmsJ3zwmGglvL6AUtu2jnV', n_files=None, n_observations=8874, branch_id=1, created_on_id=1, space_id=1, storage_id=1, run_id=56, schema_id=None, created_by_id=5, created_at=2026-03-20 19:44:42 UTC, is_locked=False, version_tag=None, is_latest=True)
13.6. References#
Tamim Abdelaal, Lieke Michielsen, Davy Cats, Dylan Hoogduin, Hailiang Mei, Marcel J. T. Reinders, and Ahmed Mahfouz. A comparison of automatic cell identification methods for single-cell rna sequencing data. Genome Biology, 20(1):194, Sep 2019. URL: https://doi.org/10.1186/s13059-019-1795-z, doi:10.1186/s13059-019-1795-z.
C. Domínguez Conde, C. Xu, L. B. Jarvis, D. B. Rainbow, S. B. Wells, T. Gomes, S. K. Howlett, O. Suchanek, K. Polanski, H. W. King, L. Mamanova, N. Huang, P. A. Szabo, L. Richardson, L. Bolt, E. S. Fasouli, K. T. Mahbubani, M. Prete, L. Tuck, N. Richoz, Z. K. Tuong, L. Campos, H. S. Mousa, E. J. Needham, S. Pritchard, T. Li, R. Elmentaite, J. Park, E. Rahmani, D. Chen, D. K. Menon, O. A. Bayraktar, L. K. James, K. B. Meyer, N. Yosef, M. R. Clatworthy, P. A. Sims, D. L. Farber, K. Saeb-Parsy, J. L. Jones, and S. A. Teichmann. Cross-tissue immune cell analysis reveals tissue-specific features in humans. Science, 376(6594):eabl5197, 2022. URL: https://www.science.org/doi/abs/10.1126/science.abl5197, arXiv:https://www.science.org/doi/pdf/10.1126/science.abl5197, doi:10.1126/science.abl5197.
Jan Engelmann, Leon Hetzel, Giovanni Palla, Lisa Sikkema, Malte Luecken, and Fabian Theis. Uncertainty quantification for atlas-level cell type transfer. 2022. URL: https://arxiv.org/abs/2211.03793, doi:10.48550/ARXIV.2211.03793.
Rui Fu, Austin E. Gillen, Ryan M. Sheridan, Chengzhe Tian, Michelle Daya, Yue Hao, Jay R. Hesselberth, and Kent A. Riemondy. Clustifyr: an r package for automated single-cell RNA sequencing cluster classification. F1000Research, 9:223, July 2020. URL: https://doi.org/10.12688/f1000research.22969.2, doi:10.12688/f1000research.22969.2.
Yuhan Hao, Stephanie Hao, Erica Andersen-Nissen, William M. Mauck, Shiwei Zheng, Andrew Butler, Maddie J. Lee, Aaron J. Wilk, Charlotte Darby, Michael Zager, Paul Hoffman, Marlon Stoeckius, Efthymia Papalexi, Eleni P. Mimitou, Jaison Jain, Avi Srivastava, Tim Stuart, Lamar M. Fleming, Bertrand Yeung, Angela J. Rogers, Juliana M. McElrath, Catherine A. Blish, Raphael Gottardo, Peter Smibert, and Rahul Satija. Integrated analysis of multimodal single-cell data. Cell, 184(13):3573–3587.e29, 2021. URL: https://www.sciencedirect.com/science/article/pii/S0092867421005833, doi:https://doi.org/10.1016/j.cell.2021.04.048.
Yixuan Huang and Peng Zhang. Evaluation of machine learning approaches for cell-type identification from single-cell transcriptomics data. Briefings in Bioinformatics, February 2021. URL: https://doi.org/10.1093/bib/bbab035, doi:10.1093/bib/bbab035.
Ignacio Isola, Fara Brasó-Maristany, David F. Moreno, Mari-Pau Mena, Aina Oliver-Calders, Laia Paré, Luis Gerardo Rodríguez-Lobato, Beatriz Martin-Antonio, María Teresa Cibeira, Joan Bladé, Laura Rosiñol, Aleix Prat, Ester Lozano, and Carlos Fernández De Larrea. Gene Expression Analysis of the Bone Marrow Microenvironment Reveals Distinct Immunotypes in Smoldering Multiple Myeloma Associated to Progression to Symptomatic Disease. Frontiers in Immunology, 12:792609, November 2021. doi:10.3389/fimmu.2021.792609.
Preetish Kadur Lakshminarasimha Murthy, Vishwaraj Sontake, Aleksandra Tata, Yoshihiko Kobayashi, Lauren Macadlo, Kenichi Okuda, Ansley S. Conchola, Satoko Nakano, Simon Gregory, Lisa A. Miller, Jason R. Spence, John F. Engelhardt, Richard C. Boucher, Jason R. Rock, Scott H. Randell, and Purushothama Rao Tata. Human distal lung maps and lineage hierarchies reveal a bipotent progenitor. Nature, 604(7904):111–119, Apr 2022. URL: https://doi.org/10.1038/s41586-022-04541-3, doi:10.1038/s41586-022-04541-3.
Joyce B. Kang, Aparna Nathan, Kathryn Weinand, Fan Zhang, Nghia Millard, Laurie Rumker, D. Branch Moody, Ilya Korsunsky, and Soumya Raychaudhuri. Efficient and precise single-cell reference atlas mapping with symphony. Nature Communications, 12(1):5890, Oct 2021. URL: https://doi.org/10.1038/s41467-021-25957-x, doi:10.1038/s41467-021-25957-x.
Romain Lopez, Jeffrey Regier, Michael B Cole, Michael I Jordan, and Nir Yosef. Deep generative modeling for single-cell transcriptomics. Nat. Methods, 15(12):1053–1058, December 2018.
Mohammad Lotfollahi, Mohsen Naghipourfar, Malte D. Luecken, Matin Khajavi, Maren Büttner, Marco Wagenstetter, Žiga Avsec, Adam Gayoso, Nir Yosef, Marta Interlandi, Sergei Rybakov, Alexander V. Misharin, and Fabian J. Theis. Mapping single-cell data to reference atlases by transfer learning. Nature Biotechnology, 40(1):121–130, Jan 2022. URL: https://doi.org/10.1038/s41587-021-01001-7, doi:10.1038/s41587-021-01001-7.
Giovanni Pasquini, Jesus Eduardo Rojo Arias, Patrick Schäfer, and Volker Busskamp. Automated methods for cell type annotation on scrna-seq data. Computational and Structural Biotechnology Journal, 19:961–969, 2021. URL: https://www.sciencedirect.com/science/article/pii/S2001037021000192, doi:https://doi.org/10.1016/j.csbj.2021.01.015.
Hannah A. Pliner, Jay Shendure, and Cole Trapnell. Supervised classification enables rapid annotation of cell atlases. Nature Methods, 16(10):983–986, Oct 2019. URL: https://doi.org/10.1038/s41592-019-0535-3, doi:10.1038/s41592-019-0535-3.
Jeffrey M. Pullin and Davis J. McCarthy. A comparison of marker gene selection methods for single-cell rna sequencing data. bioRxiv, 2022. URL: https://www.biorxiv.org/content/early/2022/05/10/2022.05.09.490241, arXiv:https://www.biorxiv.org/content/early/2022/05/10/2022.05.09.490241.full.pdf, doi:10.1101/2022.05.09.490241.
Lisa Sikkema, Ciro Ram\'ırez-Suástegui, Daniel C. Strobl, Tessa E. Gillett, Luke Zappia, Elo Madissoon, Nikolay S. Markov, Laure-Emmanuelle Zaragosi, Yuge Ji, Meshal Ansari, Marie-Jeanne Arguel, Leonie Apperloo, Martin Banchero, Christophe Bécavin, Marijn Berg, Evgeny Chichelnitskiy, Mei-i Chung, Antoine Collin, Aurore C. A. Gay, Janine Gote-Schniering, Baharak Hooshiar Kashani, Kemal Inecik, Manu Jain, Theodore S. Kapellos, Tessa M. Kole, Sylvie Leroy, Christoph H. Mayr, Amanda J. Oliver, Michael von Papen, Lance Peter, Chase J. Taylor, Thomas Walzthoeni, Chuan Xu, Linh T. Bui, Carlo De Donno, Leander Dony, Alen Faiz, Minzhe Guo, Austin J. Gutierrez, Lukas Heumos, Ni Huang, Ignacio L. Ibarra, Nathan D. Jackson, Preetish Kadur Lakshminarasimha Murthy, Mohammad Lotfollahi, Tracy Tabib, Carlos Talavera-López, Kyle J. Travaglini, Anna Wilbrey-Clark, Kaylee B. Worlock, Masahiro Yoshida, Yuexin Chen, James S. Hagood, Ahmed Agami, Peter Horvath, Joakim Lundeberg, Charles-Hugo Marquette, Gloria Pryhuber, Chistos Samakovlis, Xin Sun, Lorraine B. Ware, Kun Zhang, Maarten van den Berge, Yohan Bossé, Tushar J. Desai, Oliver Eickelberg, Naftali Kaminski, Mark A. Krasnow, Robert Lafyatis, Marko Z. Nikolic, Joseph E. Powell, Jayaraj Rajagopal, Mauricio Rojas, Orit Rozenblatt-Rosen, Max A. Seibold, Dean Sheppard, Douglas P. Shepherd, Don D. Sin, Wim Timens, Alexander M. Tsankov, Jeffrey Whitsett, Yan Xu, Nicholas E. Banovich, Pascal Barbry, Thu Elizabeth Duong, Christine S. Falk, Kerstin B. Meyer, Jonathan A. Kropski, Dana Pe'er, Herbert B. Schiller, Purushothama Rao Tata, Joachim L. Schultze, Sara A. Teichmann, Alexander V. Misharin, Martijn C. Nawijn, Malte D. Luecken, and Fabian J. Theis and. An integrated cell atlas of the lung in health and disease. Nature Medicine, June 2023. URL: https://doi.org/10.1038/s41591-023-02327-2, doi:10.1038/s41591-023-02327-2.
V. A. Traag, L. Waltman, and N. J. van Eck. From louvain to leiden: guaranteeing well-connected communities. Scientific Reports, 9(1):5233, Mar 2019. URL: https://doi.org/10.1038/s41598-019-41695-z, doi:10.1038/s41598-019-41695-z.
Allon Wagner, Aviv Regev, and Nir Yosef. Revealing the vectors of cellular identity with single-cell genomics. Nature Biotechnology, 34(11):1145–1160, Nov 2016. URL: https://doi.org/10.1038/nbt.3711, doi:10.1038/nbt.3711.
Hongkui Zeng. What is a cell type and how to define it? Cell, 185(15):2739–2755, 2022. URL: https://www.sciencedirect.com/science/article/pii/S0092867422007838, doi:https://doi.org/10.1016/j.cell.2022.06.031.
Allen W. Zhang, Ciara O'Flanagan, Elizabeth A. Chavez, Jamie L. P. Lim, Nicholas Ceglia, Andrew McPherson, Matt Wiens, Pascale Walters, Tim Chan, Brittany Hewitson, Daniel Lai, Anja Mottok, Clementine Sarkozy, Lauren Chong, Tomohiro Aoki, Xuehai Wang, Andrew P. Weng, Jessica N. McAlpine, Samuel Aparicio, Christian Steidl, Kieran R. Campbell, and Sohrab P. Shah. Probabilistic cell-type assignment of single-cell rna-seq for tumor microenvironment profiling. Nature Methods, 16(10):1007–1015, Oct 2019. URL: https://doi.org/10.1038/s41592-019-0529-1, doi:10.1038/s41592-019-0529-1.
Jesse M. Zhang, Govinda M. Kamath, and David N. Tse. Valid post-clustering differential analysis for single-cell rna-seq. Cell Systems, 9(4):383–392.e6, 2019. URL: https://www.sciencedirect.com/science/article/pii/S2405471219302698, doi:https://doi.org/10.1016/j.cels.2019.07.012.
13.7. Contributors#
We gratefully acknowledge the contributions of:
13.7.2. Reviewers#
Lukas Heumos