35. Doublet detection#
Key takeaways
Heterotypic doublets in ADT data can be identified and removed using mutually exclusive cell type markers (e.g., CD3, CD19, CD14), with cells expressing both markers likely representing doublets.
Environment setup
Install conda:
Before creating the environment, ensure that conda is installed on your system.
Save the yml content:
Copy the content from the yml tab into a file named
environment.yml.
Create the environment:
Open a terminal or command prompt.
Run the following command:
conda env create -f environment.yml
Activate the environment:
After the environment is created, activate it using:
conda activate <environment_name>
Replace
<environment_name>with the name specified in theenvironment.ymlfile. In the yml file it will look like this:name: <environment_name>
Verify the installation:
Check that the environment was created successfully by running:
conda env list
name: surface-protein
channels:
- conda-forge
- bioconda
dependencies:
- scanpy=1.9.1
- muon=0.1.5
- harmonypy=0.0.9
- glob2
- leidenalg
- numba>=0.56.4
- pooch=1.7.0
35.1. Motivation#
So far, we have removed cells that potentially reflect doublets based only on their high count content. We have also filtered based on sample-wise distribution. Now, we will focus on heterotypic doublets. With ADT data, we can detect them using cell type specific surface markers[].
35.2. Environment setup#
import muon as mu
import pooch
import scanpy as sc
# setting visualization parameters
sc.settings.verbosity = 0
sc.settings.set_figure_params(
dpi=80,
facecolor="white",
frameon=False,
)
35.3. Loading the data#
cite_filtered = pooch.retrieve(
url="https://figshare.com/ndownloader/files/41452443",
fname="cite_normalization.h5mu",
path=".",
known_hash=None,
progressbar=True,
)
mdata = mu.read("cite_normalization.h5mu")
35.4. Doublets detected with cell type markers#
We are now going to look at cell type markers that are mutually exclusive. Some examples are CD3 (T cell marker) vs CD19 (B cell marker) to identify T/B cells doublets. As cells expressing both specific B and T cell markers do not exist in the physiological condition, those droplets most likely contain more than one cell.
The same is true for cells both expressing T cell (CD3) and Monocyte (CD14) markers.
mdata
MuData object with n_obs × n_vars = 120502 × 36741
var: 'gene_ids', 'feature_types'
2 modalities
rna: 120502 x 36601
obs: 'donor', 'batch'
var: 'gene_ids', 'feature_types'
prot: 120502 x 140
obs: 'donor', 'batch', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'n_counts', 'outliers'
var: 'gene_ids', 'feature_types', 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts'
layers: 'counts'sc.pl.scatter(mdata["prot"], x="CD3", y="CD19-1", color="log1p_total_counts")
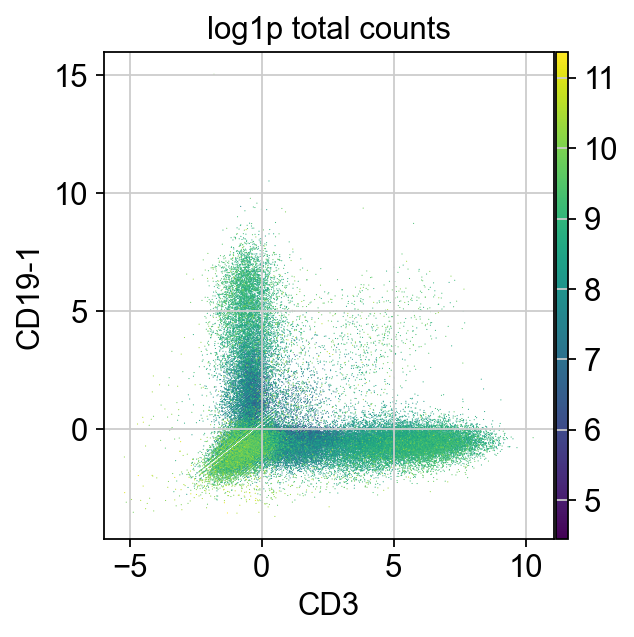
In this plot, we can see a large number of cells not expressing T or B cell markers in the lower left, cells expressing only one marker in the upper left and lower right as well as some cells expressing both markers (upper right).
The cells expressing both markers are most likely doublets and can be removed.
We can also use CD3 and CD14 to detect T/Monocytes doublets.
sc.pl.scatter(mdata["prot"], x="CD3", y="CD14-1", color="log1p_total_counts")
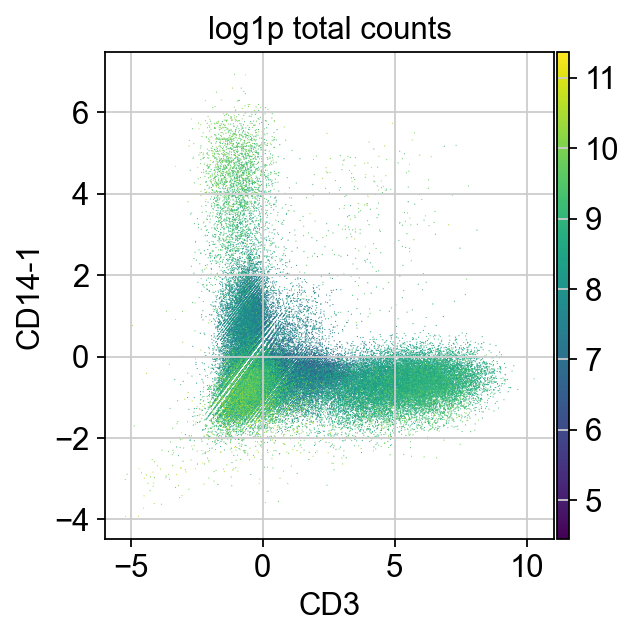
It looks like the change in distribution is around 2.5. We could use an expression level above 2.5 of at least two incompatible markers as our threshold to flag doublets.
genes2filter = ["CD3", "CD19-1", "CD14-1"]
temp = mdata["prot"][:, genes2filter].X.T.tolist()
mdata["prot"].obs["doublets_markers"] = [
(temp[0][i] > 2.5 and temp[1][i] > 2.5) or (temp[0][i] > 2.5 and temp[2][i] > 2.5)
for i in range(mdata.shape[0])
]
mdata["prot"].obs["doublets_markers"] = (
mdata["prot"].obs["doublets_markers"].astype(str)
)
We leave out cells expressing both markers.
sc.pl.violin(mdata["prot"], keys="log1p_total_counts", groupby="doublets_markers")
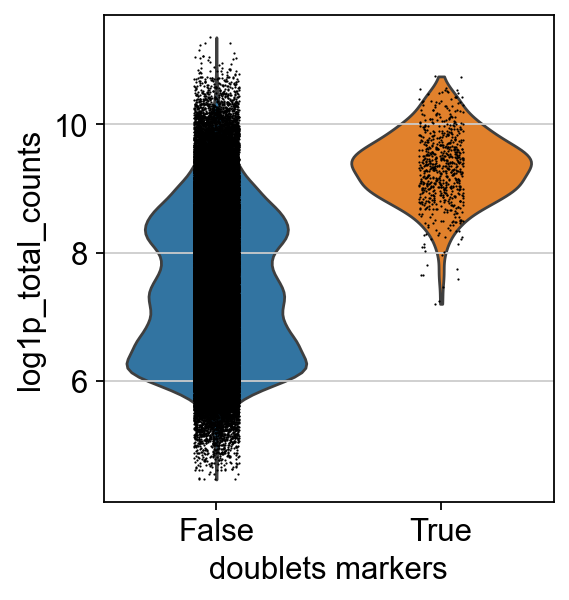
Doublets usually have a higher count due to the presence of increased counts from more than one cell. We can see this effect in the cells classified as doublets using our markers.
mdata.update()
mdata = mdata[mdata.obs.loc[mdata["prot"].obs_names].index]
mdata = mdata[mdata["prot"].obs["doublets_markers"] == "False"].copy()
mdata
MuData object with n_obs × n_vars = 119837 × 36741
var: 'gene_ids', 'feature_types'
2 modalities
rna: 119837 x 36601
obs: 'donor', 'batch'
var: 'gene_ids', 'feature_types'
prot: 119837 x 140
obs: 'donor', 'batch', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'n_counts', 'outliers', 'doublets_markers'
var: 'gene_ids', 'feature_types', 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts'
uns: 'doublets_markers_colors'
layers: 'counts'mdata.write("cite_doublet_removal_xdbt.h5mu")
35.5. References#
35.6. Contributors#
We gratefully acknowledge the contributions of:
35.6.2. Reviewers#
Lukas Heumos
Anna Schaar