27. Gene regulatory networks#
Key takeaways
We prepared an RNA and ATAC object using R, for processing with FigR and CisTopic.
We calculated DORC scores with FigR, and visualized those as scatter, heatmap and networks.
Environment setup
Install conda:
Before creating the environment, ensure that conda is installed on your system.
Save the yml content:
Copy the content from the yml tab into a file named
environment.yml.
Create the environment:
Open a terminal or command prompt.
Run the following command:
conda env create -f environment.yml
Activate the environment:
After the environment is created, activate it using:
conda activate <environment_name>
Replace
<environment_name>with the name specified in theenvironment.ymlfile. In the yml file it will look like this:name: <environment_name>
Verify the installation:
Check that the environment was created successfully by running:
conda env list
name: gene-regulatory-networks-atac
channels:
- conda-forge
- anaconda
- bioconda
dependencies:
- conda-forge::python=3.8 # this package version is required for figR
- conda-forge::r-base=4.2.2
- conda-forge::r-umap
- conda-forge::r-devtools
- conda-forge::r-cairo
- conda-forge::r-ggrastr
- conda-forge::r-patchwork
- conda-forge::r-gplots
- conda-forge::r-networkd3 # network viz
- conda-forge::r-r2d3 # network viz
- conda-forge::r-webshot # network viz
- conda-forge::phantomjs # network viz
- conda-forge::r-imager # network viz
- conda-forge::jupyterlab
- conda-forge::jupyter_server=1.18.1
- conda-forge::r-rmpfr
- conda-forge::r-irkernel
- conda-forge::r-dplyr
- bioconda::bioconductor-zellkonverter>=1.8
# - bioconda::bioconductor-bsgenome.hsapiens.ucsc.hg38=1.4.4 # this package will have to be installed while running
- bioconda::bioconductor-complexheatmap
- bioconda::bioconductor-motifmatchr
- bioconda::bioconductor-rcistarget
- bioconda::bioconductor-chromvar
27.1. Motivation#
Analyzing chromatin accessibility and gene expression together to understand gene regulation is helpful due to the mechanistic relationship between those two during the control of gene regulation, mediated through transcription factors (TFs) and other epigenetic modulators [Spitz and Furlong, 2012]. Briefly, regulatory regions annotated as promoters and local/distal enhancers are engaged during the early phases of gene expression regulation, and chromatin accessibility increase, or decrease, can be used as a proxy for changes in their activity. Hence, the global positive or negative correlation between proximal and distal accessible elements (measured by ATAC-seq) and target genes (measured by RNA-seq) within a genome neighborhood distance (e.g. less than 200 Kbp), serves to annotate genomic regulatory relationships during the inference of Gene Regulatory Networks (GRNs). Using sequencing data describing gene (RNA) and peak (ATAC) features, tools that build correlation matrices between peaks and matrices help summarize strong peak-gene interactions.
27.1.1. Gene regulatory network inference using RNA and ATAC features#
In this notebook, we will use the package FigR [Kartha et al., 2022] to describe such GRN-building steps on a donor of the NeurIPs dataset. Preparation scripts of this notebook will also call cisTopic [Bravo González-Blas et al., 2019] to generate peak clusters or topics from the ATAC seq counts matrix. During the calculation of RNA-ATAC correlations, FigR uses ChromVAR [Schep et al., 2017] to map Transcription Factor motifs to the mapped peaks. The main processing steps described in this notebook are adapted based on FigR’s core tutorial for SHARE-seq data Tutorial
Disclaimer: At the time of writing this chapter, several methods that utilize single-cell RNA and ATAC information for GRN inference are currently available. Due to similar benchmarking reasons as the one indicated in the previous chapter, we cannot say that these methods will perform best in the majority of scenarios. We globally recommend either of those as a starting point, given available data, to infer preliminary GRNs.
27.1.2. Install and load FigR package#
# the installation of this package is required for the proper execution of this notebook.
if(!suppressMessages(require("FigR"))){
suppressMessages(devtools::install_github("caleblareau/BuenColors")) # the package BuenColors is also a devtools dependency to install FigR.
suppressMessages(devtools::install_github("buenrostrolab/FigR"))
}
suppressMessages(library(FigR))
27.1.3. Use zellkonverter to convert h5ad to SingleCellExperiment#
library(zellkonverter)
library(SingleCellExperiment)
Load the full NeurIPs dataset using zellkonverter. Then, subset for one donor (s1d1) using the batch column. This donor will be the one used in this tutorial.
sce <- readH5AD("../../data/openproblems_bmmc_multiome_genes_filtered.h5ad")
sce <- sce[colData(sce)$batch == 's1d1',]
For faster computing, we define a subset of features
ncells = -1 # if using all cells
nfeatures_rna = 10000 # -1 if using all rna features
nfeatures_atac = 10000 # -1 if using all atac features
Once donor s1d1 is subset, divide features by RNA and ATAC into two objects
(in case of a new index, it can be checked with rownames(sce))
RNA <- sce[1:13431,]
ATAC <- sce[13432:nrow(sce),]
Download the list of TFs annotations for hg38, using the same gene labels as the RNA-only tutorial. Other annotations, such as HumanTFs, can also be used.
if(!file.exists('allTFs_hg38.txt'))
download.file('https://raw.githubusercontent.com/aertslab/SCENICprotocol/master/example/allTFs_hg38.txt', 'allTFs_hg38.txt')
tf_names = rownames(read.table('allTFs_hg38.txt', row.names=1))
print(length(tf_names))
[1] 1797
# subset by cells:
if(ncells != -1){
RNA <- RNA[,1:ncells]
ATAC <- ATAC[,1:ncells]
}
if(nfeatures_rna != -1){
# select all TFs and a subset of non-TFs
is_tf <- rownames(RNA) %in% tf_names
index_tf <- which(is_tf)
index_not_tf <- which(!is_tf)
set.seed(nfeatures_rna)
RNA <- RNA[c(index_tf, sample(index_not_tf, nfeatures_rna - length(index_tf))),]
}
Selection of peaks, based on the coefficient of variation criterion, adapted from the EpiScanpy’s implementation
if(nfeatures_atac != -1){
frac_atac <- rowSums(assay(ATAC)) / ncol(ATAC)
acc_score <- abs(0.5 - frac_atac)
peak_mask <- rownames(ATAC) %in% names(sort(acc_score))[1:nfeatures_atac]
ATAC <- ATAC[peak_mask,]
}
print(c(dim(ATAC), dim(RNA)))
is_tf <- rownames(RNA) %in% tf_names
[1] 10000 6224 10000 6224
UMAP <- reducedDim(ATAC, 'GEX_X_umap')
# counts variable (for later functions)
assay(ATAC) <- as(assay(ATAC), 'sparseMatrix')
counts(ATAC) <- assay(ATAC)
Preprocessing of SummarizedExperimentObject using the number of cells
# Remove genes with zero expression across all cells
# RNA <- RNA[Matrix::rowSums(RNA) != 0,]
27.1.4. Preparation and execution of cisTopic#
cisTopic applies Latent Dirichlet allocation to define a number of “topics” that are able to summarize the variability of the observed chromatin accessibility counts retrieved by ATAC-seq. Here, we install, calculate of the cisTopic object using scATAC-seq, and use it downstream as input for FigR.
Installation of cisTopic through devtools (if required). This installation takes approximately ten minutes, due to cisTopic-specific dependencies. (restart of kernel might be required)
if(!suppressMessages(require("cisTopic")))
suppressMessages(devtools::install_github("aertslab/cisTopic"))
suppressMessages(library(cisTopic))
The following script requires indicating a number of cores (nCores). Increase according to computing resources available
nCores = 2
cistopic_bkp_path <- "../../data/openproblems_bmmc_multiome_genes_filtered_atac_s1d1_counts_cisTopic.rds"
if(nfeatures_atac != -1)
cistopic_bkp_path <- paste0("../../data/openproblems_bmmc_multiome_genes_filtered_atac_s1d1_counts_cisTopic_npeaks", nfeatures_atac, ".rds")
print(c(file.exists(cistopic_bkp_path), cistopic_bkp_path))
[1] "TRUE"
[2] "../../data/openproblems_bmmc_multiome_genes_filtered_atac_s1d1_counts_cisTopic_npeaks10000.rds"
This analysis through cisTopic allows us to retrieve and interpret two specific values, as line plots:
A curve showing the main log-likelihood calculated by cisTopic, versus the number of topics. A plateau of this curve number indicates that additional topics are not main factors to explain the data, versus previous topics.
The first derivative of likelihood versus number of declared topics. This visualization is useful to assess convergence in the likelihood value, and random oscillations around zero, as the number of topics increases.
overwrite = TRUE # to visualize plots, this will always execute. Modify to FALSE to avoid replacing output from previous runs.
if(!file.exists(cistopic_bkp_path) || overwrite){
# the number of topics to test
n_topics = 1:25
atac <- as.matrix(counts(ATAC))
atac <- as.data.frame(atac)
# we need to work out the names of the rownames, and replace - into : to match the chromosome:start-end required format by cisTopic
chr <- sapply(strsplit(rownames(atac),"-"), `[`, 1)
start <- sapply(strsplit(rownames(atac),"-"), `[`, 2)
end <- sapply(strsplit(rownames(atac),"-"), `[`, 3)
rownames(atac) <- paste0(chr, ':', start, '-', end)
cisTopicObject <- createcisTopicObject(atac, project.name='neurips_s1d1')
cisTopicObject <- runCGSModels(cisTopicObject, topic=c(n_topics), # , 5:15, 20, 25), # topic=c(2, 5:15, 20, 25),
seed=987, nCores=nCores, burnin = 90,
iterations = 100, addModels=FALSE)
cisTopicObject <- selectModel(cisTopicObject, type='maximum')
# cisTopicObject
cisTopicObject <- runUmap(cisTopicObject, target='cell')
topic.mat <- modelMatSelection(cisTopicObject, 'cell', 'Probability')
topic.mat <- t(topic.mat)
topic.mat <- as.matrix(topic.mat)
saveRDS(topic.mat, cistopic_bkp_path)
}
[1] "Formatting data..."
[1] "Exporting data..."
[1] "Running models..."
Loading required package: umap
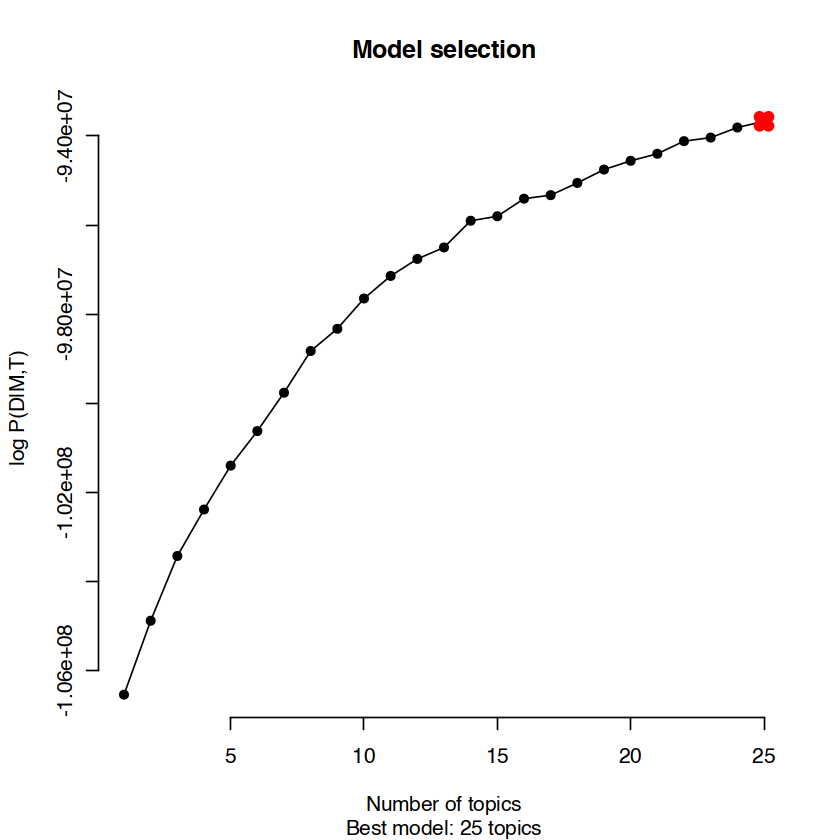
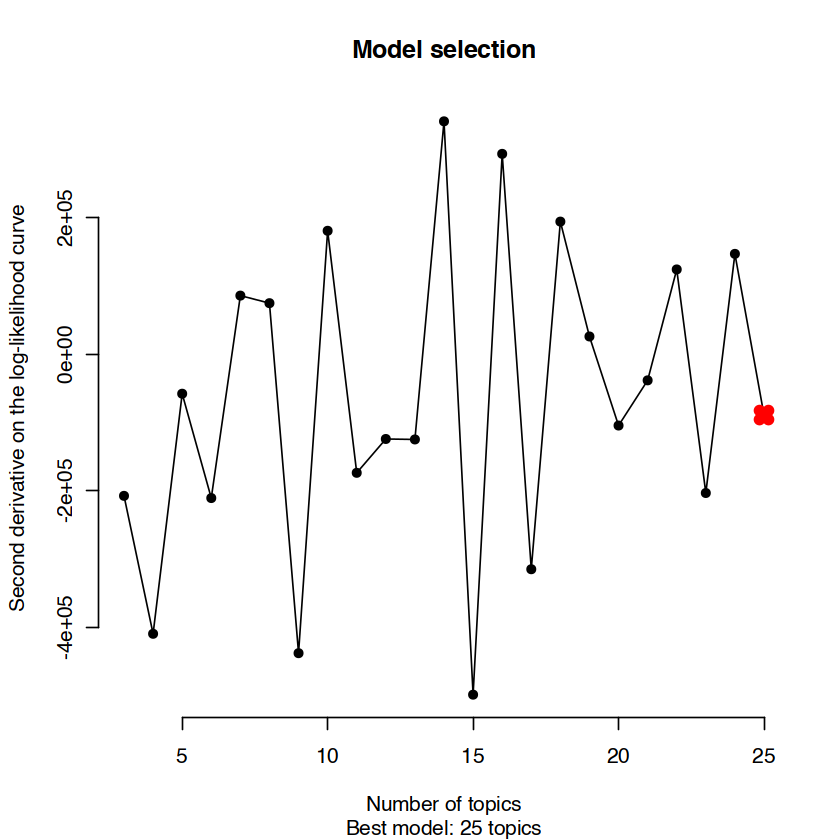
Once the CisTopic object is generated, we can use it to extract relevant features
cisAssign <- readRDS(cistopic_bkp_path)
dim(cisAssign) # Cells x Topics
- 6224
- 25
Calculate a kNN-graph using the topics matrix from cisTopic
library(dplyr)
library(FNN)
set.seed(123)
cellkNN <- get.knn(cisAssign, k = 30)$nn.index
dim(cellkNN)
- 6224
- 30
Visualization of cells using the embedding generated by UMAP
colData(ATAC)$cellAnnot <- colData(ATAC)$cell_type
colData(ATAC)$UMAP1 <- UMAP[,1]
colData(ATAC)$UMAP2 <- UMAP[,2]
# Plot
library(ggplot2)
options(repr.plot.width=12, repr.plot.height=6)
colData(ATAC) %>% as.data.frame() %>% ggplot(aes(UMAP1,UMAP2,color=cellAnnot)) +
geom_point(size=0.5) + # scale_color_manual(values=annoCols)+
theme_classic() + guides(colour = guide_legend(override.aes = list(size=2))) + cowplot::theme_cowplot(font_family='Sans')
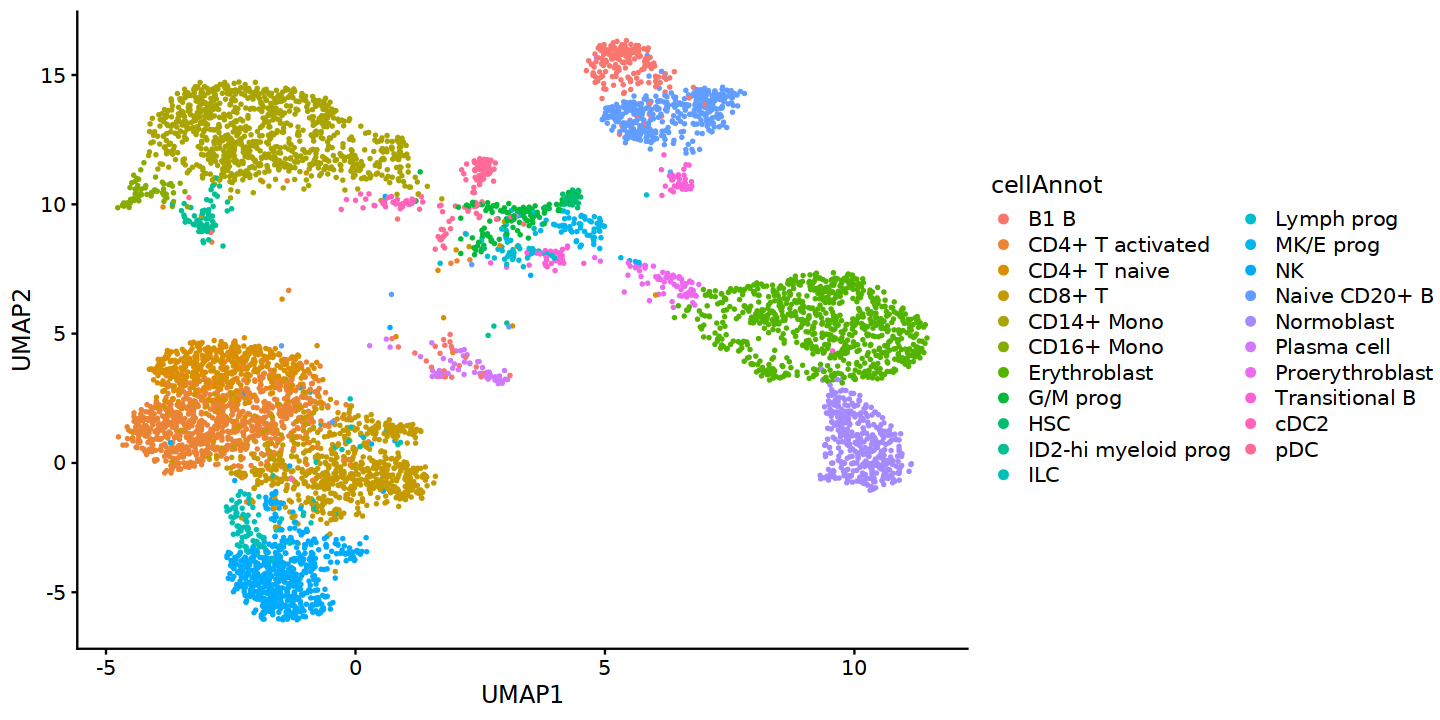
Preparation of input data is finished. Now, the execution of the FigR algorithm begins.
# if the hg38 genome is not installed successfully during environment building, it can be installed here.
# this might require a kernel restart
if(!suppressMessages(require('BSgenome.Hsapiens.UCSC.hg38'))){
if (!require("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("BSgenome.Hsapiens.UCSC.hg38")
}
suppressMessages(library(BSgenome.Hsapiens.UCSC.hg38))
# check object dimensions
c(dim(ATAC), dim(RNA))
- 10000
- 6224
- 10000
- 6224
The following script requires indicating a number of cores (nCores). Increase according to computing resources available
Prepare data for runGenePeakcorr
library(Matrix)
RNAmat <- as.matrix(assay(RNA))
dim(RNAmat)
- 10000
- 6224
ATAC_df <- as.data.frame(as.matrix(counts(ATAC)))
# df <- as.data.frame(as.matrix(counts(ATAC)))
ATAC_df$seqnames <- sapply(strsplit(rownames(ATAC_df),"-"), `[`, 1)
ATAC_df$start <- sapply(strsplit(rownames(ATAC_df),"-"), `[`, 2)
ATAC_df$end <- sapply(strsplit(rownames(ATAC_df),"-"), `[`, 3)
ATAC_df <- subset(ATAC_df, grepl('chr', rownames(ATAC_df)))
dim(ATAC_df)
- 9997
- 6227
ATAC.se <- makeSummarizedExperimentFromDataFrame(ATAC_df)
counts(ATAC.se) <- assay(ATAC.se)
assay(ATAC.se) <- as(assay(ATAC.se), 'sparseMatrix')
Run runGenePeakcorr function from FigR using 2 cores
# This snippet can be run interactively, but it takes a long time.
nCores = 2
bkp_path_ciscorr <- '../../data/openproblems_bmmc_multiome_genes_filtered_s1d1_ciscorr.rds'
if(nfeatures_atac != -1)
cistopic_bkp_path <- paste0("../../data/openproblems_bmmc_multiome_genes_filtered_s1d1_ciscorr_npeaks", nfeatures_atac, ".rds")
if(!file.exists(bkp_path_ciscorr)){
cisCorr <- FigR::runGenePeakcorr(ATAC.se = ATAC.se,
RNAmat = RNAmat,
genome = "hg38", # One of hg19, mm10 or hg38
nCores = nCores,
p.cut = NULL, # Set this to NULL and we can filter later
n_bg = 250)
saveRDS(cisCorr, bkp_path_ciscorr)
}
cisCorr <- readRDS(bkp_path_ciscorr)
Filter relevant peak-gene correlations by p-value
cisCorr.filt <- cisCorr %>% filter(pvalZ <= 0.05)
print(c('all associations', nrow(cisCorr)))
print(c('filtered associations', nrow(cisCorr.filt)))
[1] "all associations" "3914"
[1] "filtered associations" "674"
if(nrow(cisCorr.filt) == 0)
print('increase the number of cells/peaks/genes to discover more associations')
stopifnot(nrow(cisCorr.filt) > 0)
Once the Peak and Gene correlations have been calculated, FigR groups ATAC-seq peaks into Domains of regulatory chromatin (DORCs). These groups are useful to describe relationships between the expression of TFs RNA levels with the overall change of multiple chromatin-accessible elements around a gene. Importantly, if multiple of those chromatin-accessible elements in a DORC also contain DNA-binding motifs related to the TF of interest, both lines of evidence are useful for broadly describing TF activators (TF motif enrichment and positive DORC - TF RNA correlation) or TF repressors (TF motif enrichment and negative DORC - TF RNA correlation).
The visualization below indicates the ranking of TFs by the number of peaks strongly correlated to those and provides information about which TFs are most strongly associated with DORCs.
library(ggrepel)
# Determine DORC genes
options(repr.plot.width=12, repr.plot.height=6)
cowplot_mono <- cowplot::theme_cowplot(font_family='sans')
dorcGenes <- cisCorr.filt %>% dorcJPlot(cutoff=2, # Default
returnGeneList = TRUE, family='sans') # + cowplot_mono
theme_set(theme_gray(base_family = "sans"))
dorcGenes + theme(font='roboto') # font problem during visualization of y/x axes (Roboto)
NULL
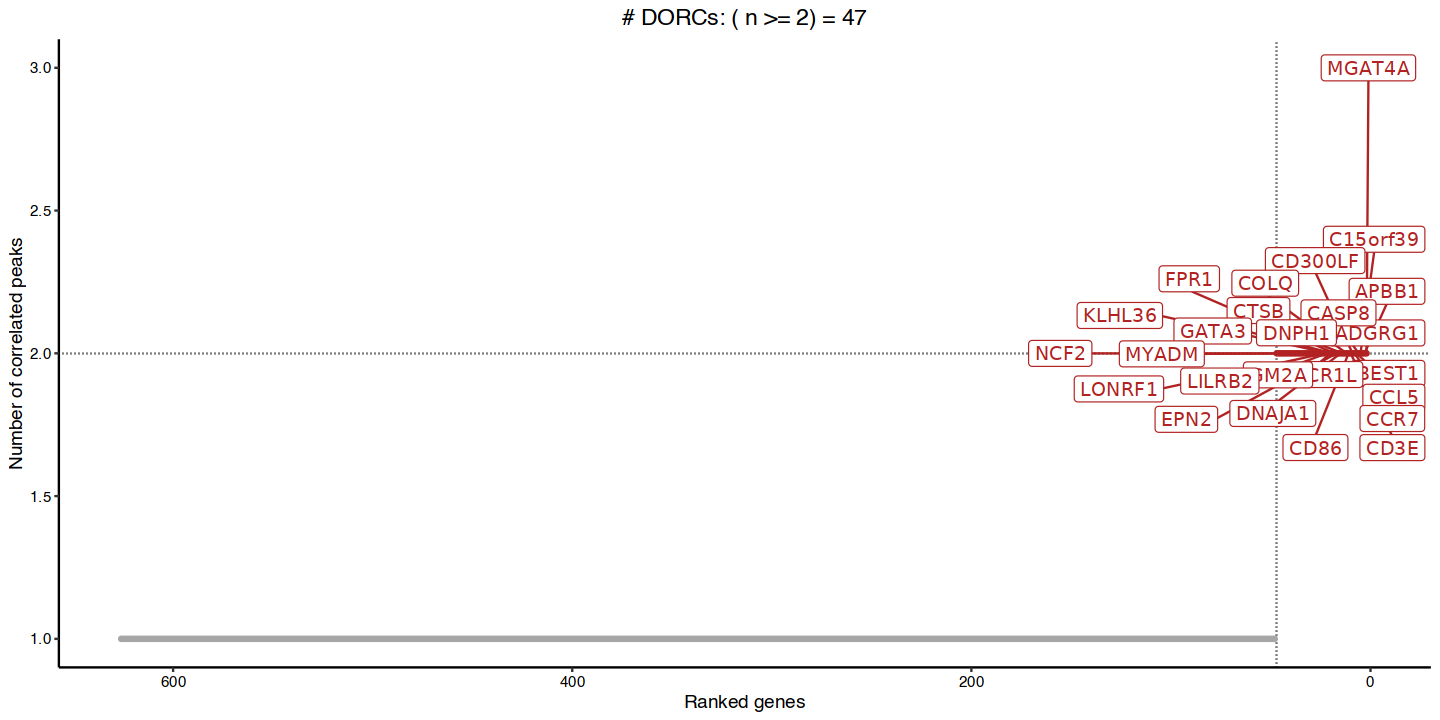
Modify the cutoff here to recover at least 30 genes. Otherwise, the runFigRGRN could not be executed.
stopifnot(length(dorcGenes) > 30)
Get DORC scores
dorcMat <- getDORCScores(ATAC.se, dorcTab=cisCorr.filt, geneList=dorcGenes, nCores=nCores)
# Smooth DORC scores (using cell KNNs)
Running DORC scoring for 47 genes: MGAT4A
ADGRG1
APBB1
BEST1
C15orf39
CASP8
CCL5
CCR7
CD300LF
CD3E
CD86
COLQ
CR1L
CTSB
DNAJA1
DNPH1
EPN2
FPR1
GATA3
GM2A
KLHL36
LILRB2
LONRF1
MYADM
NCF2
NFIA
NOLC1
P2RX1
PRF1
PRKCQ-AS1
PTCH1
RFPL1S
RHOQ
RXRA
SESN3
SLC16A6
SLC2A9
SMAD7
STRN3
SWAP70
TEC
THEMIS
TLE1
TM9SF2
TNRC6B
ZNF471
ZNRF1
........
Normalizing scATAC counts ..
SummarizedExperiment object input detected .. Centering counts under assayCentering counts for cells sequentially in groups of size 5000 ..
Computing centered counts for cells: 1 to 5000 ..
Computing centered counts per cell using mean reads in features ..
Computing centered counts for cells: 5001 to 6224 ..
Computing centered counts per cell using mean reads in features ..
Merging results..
Done!
Computing DORC scores ..
Running in parallel using 2 cores ..
Time Elapsed: 0.89201807975769 secs
stopifnot(nrow(cellkNN) == ncol(dorcMat))
rownames(cellkNN) <- colnames(dorcMat)
To execute the smoothScores NN function with multiple cores, doParallel is required.
library(doParallel)
# Smooth dorc scores using cell KNNs (k=30)
dorcMat.s <- smoothScoresNN(NNmat = cellkNN[,1:30], mat = dorcMat, nCores = nCores)
Number of cells in supplied matrix: 6224
Number of genes in supplied matrix: 47
Number of nearest neighbors being used per cell for smoothing: 30
| | 0%Running in parallel using 2 cores ..
|======================================================================| 100%
Merging results ..
Time Elapsed: 14.4018683433533 secs
stopifnot(nrow(cellkNN) == ncol(RNAmat))
rownames(cellkNN) <- colnames(RNAmat)
# Smooth RNA using cell KNNs
# This takes longer since it's all genes
RNAmat.s <- smoothScoresNN(NNmat = cellkNN[,1:30], mat = RNAmat, nCores = nCores)
Number of cells in supplied matrix: 6224
Number of genes in supplied matrix: 10000
Number of nearest neighbors being used per cell for smoothing: 30
| | 0%Running in parallel using 2 cores ..
|======================================================================| 100%
Merging results ..
Time Elapsed: 1.23741063674291 mins
library(ggplot2)
library(ggrastr)
# Visualize on pre-computed UMAP
umap.d <- as.data.frame(colData(ATAC)[,c("UMAP1","UMAP2")])
Once the DORC scores are calculated, we can explore associations between TFs and target genes, or the overall expression of TFs in each of cell types. Those two metrics contribute to an understanding of how cell types.
print(length(dorcGenes))
print(dorcGenes)
[1] 47
[1] "MGAT4A" "ADGRG1" "APBB1" "BEST1" "C15orf39" "CASP8"
[7] "CCL5" "CCR7" "CD300LF" "CD3E" "CD86" "COLQ"
[13] "CR1L" "CTSB" "DNAJA1" "DNPH1" "EPN2" "FPR1"
[19] "GATA3" "GM2A" "KLHL36" "LILRB2" "LONRF1" "MYADM"
[25] "NCF2" "NFIA" "NOLC1" "P2RX1" "PRF1" "PRKCQ-AS1"
[31] "PTCH1" "RFPL1S" "RHOQ" "RXRA" "SESN3" "SLC16A6"
[37] "SLC2A9" "SMAD7" "STRN3" "SWAP70" "TEC" "THEMIS"
[43] "TLE1" "TM9SF2" "TNRC6B" "ZNF471" "ZNRF1"
One of the genes with strong correlations with TF expression is Nuclear Factor I A (NFIA). We can inspect this case further by checking its gene expression levels and dorcGenes linked with its motif on ATAC peaks.
marker_gene = 'NFIA'
dorcg <- plotMarker2D(umap.d,dorcMat.s,markers = c(marker_gene),maxCutoff = "q0.99",
colorPalette = "brewer_heat") + ggtitle(paste0(marker_gene, ' DORC'))
Plotting NFIA
rnag <- plotMarker2D(umap.d,RNAmat.s,markers = c(marker_gene),maxCutoff = "q0.99",
colorPalette = "brewer_purple") + ggtitle(paste0(marker_gene, ' RNA'))
Plotting NFIA
Here, we visualize dorcg and rnag objects, using patchwork. This allows visual comparison of gene expression and associated DORC scores, per cell.
options(repr.plot.width=12, repr.plot.height=6)
library(patchwork)
dorcg + cowplot_mono + rnag + cowplot_mono
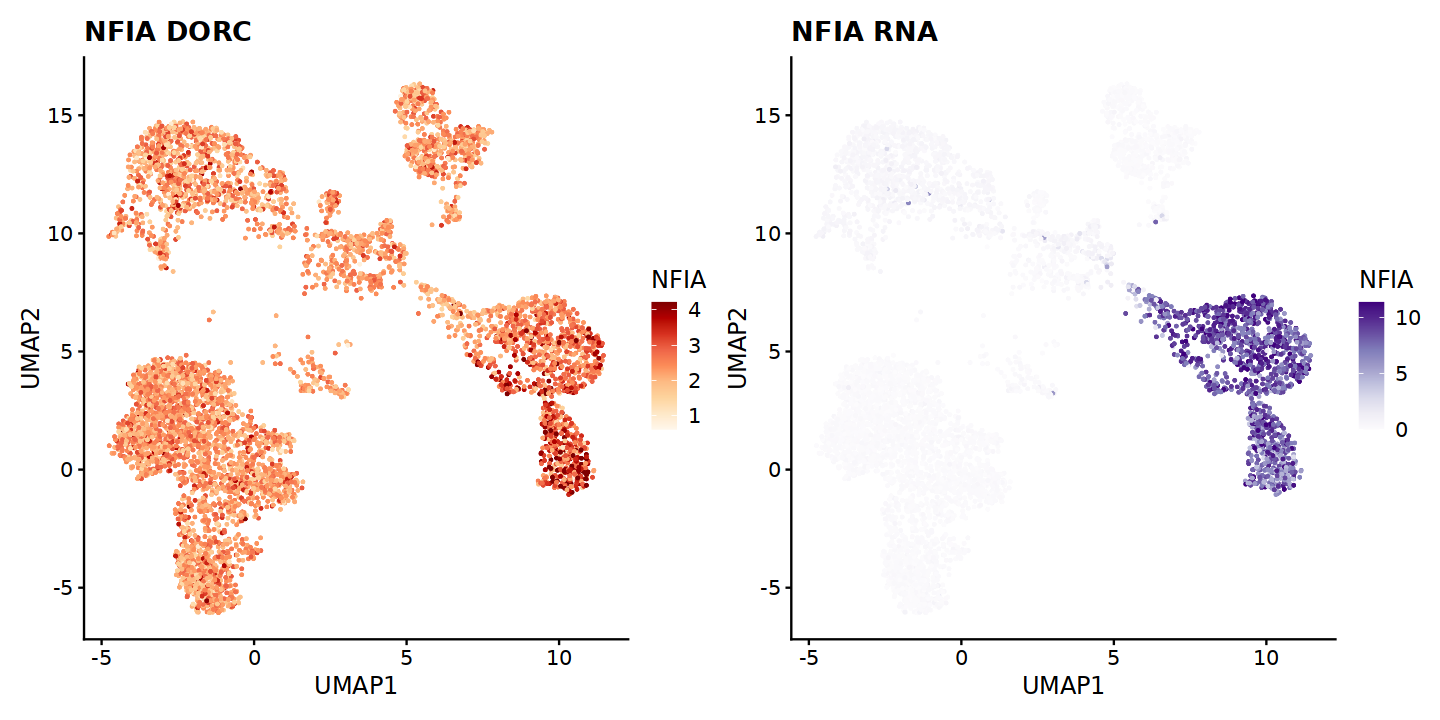
Through a visual comparison, we can identify that the agreement between NFIA expression and DORC scores is not 1-to-1, meaning that in some cell type clusters NFIA is strongly expressed, yet there is no strong correlation between those expression levels and ATAC peaks putatively occupied with NFIA.
dim(dorcMat.s)
- 47
- 6224
figR.d <- runFigRGRN(ATAC.se = ATAC.se, # Must be the same input as used in runGenePeakcorr()
dorcTab = cisCorr.filt, # Filtered peak-gene associations
genome = "hg38",
dorcMat = dorcMat.s,
rnaMat = RNAmat.s,
nCores = nCores)
Assuming peak indices in Peak field
Removing genes with 0 expression across cells ..
Getting peak x motif matches ..
Determining background peaks ..
Using 50 iterations ..
Testing 626 TFs
Testing 47 DORCs
Running FigR using 2 cores ..
|======================================================================| 100%Finished!
Merging results ..
27.2. Results visualization#
TF-DORC regulation scores (scatter plot). The y-axis indicates motif enrichment of a TF in DORCs, whereas the x-axis indicates the correlation between TF expression and those peaks (Z-test versus background). Intuitively, this visualization allows us to retrieve putative TF-activators (upper-right) and TF-repressors (upper-left).
require(ggplot2)
require(ggrastr)
require(BuenColors) # https://github.com/caleblareau/BuenColors
options(repr.plot.width=10, repr.plot.height=8)
figR.d %>%
ggplot(aes(Corr.log10P,Enrichment.log10P,color=Score)) +
ggrastr::geom_point_rast(size=0.01,shape=16) +
theme_classic() +
scale_color_gradientn(colours = jdb_palette("solar_extra"),limits=c(-3,3),oob = scales::squish,breaks=scales::breaks_pretty(n=3)) +
cowplot_mono + cowplot::theme_cowplot(font_family='sans' )
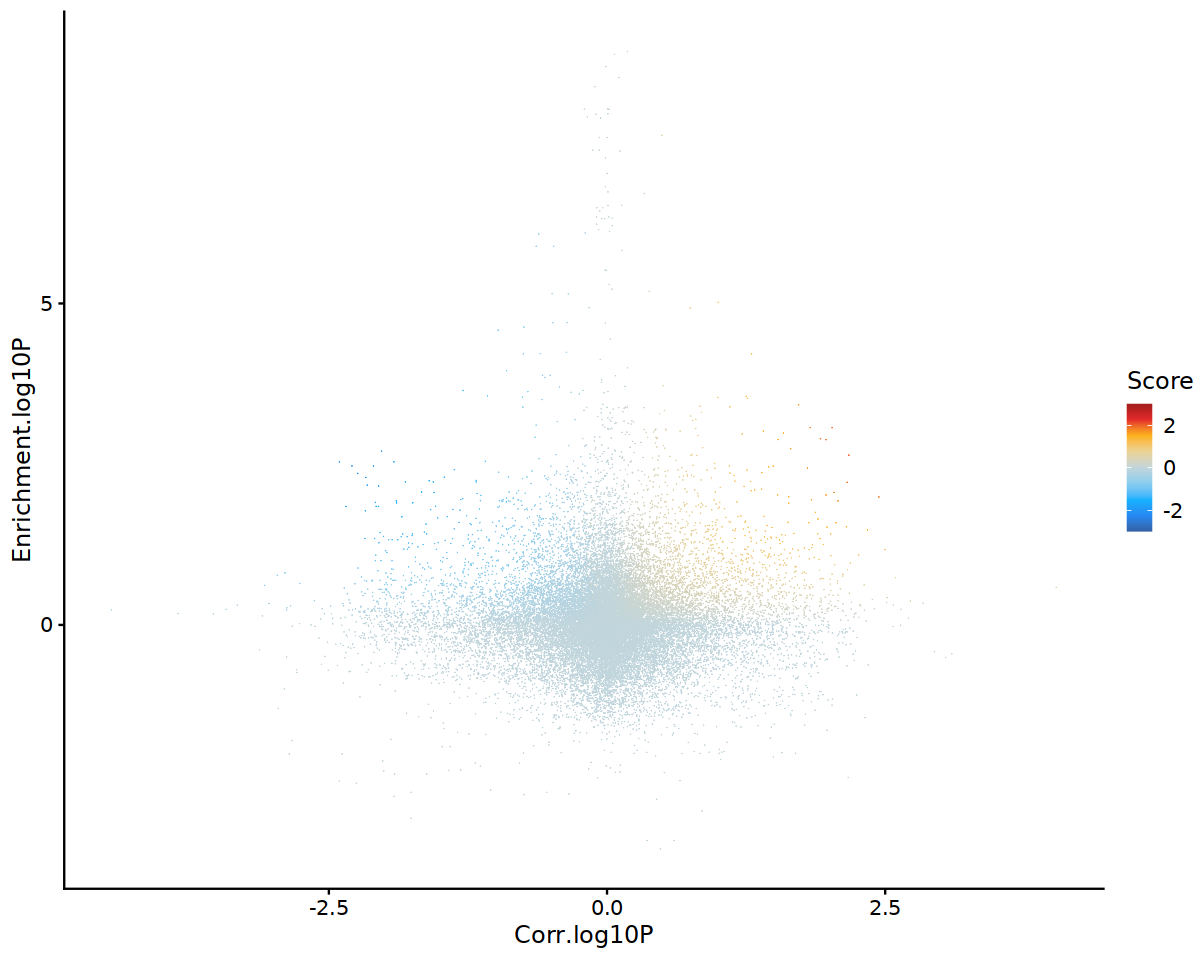
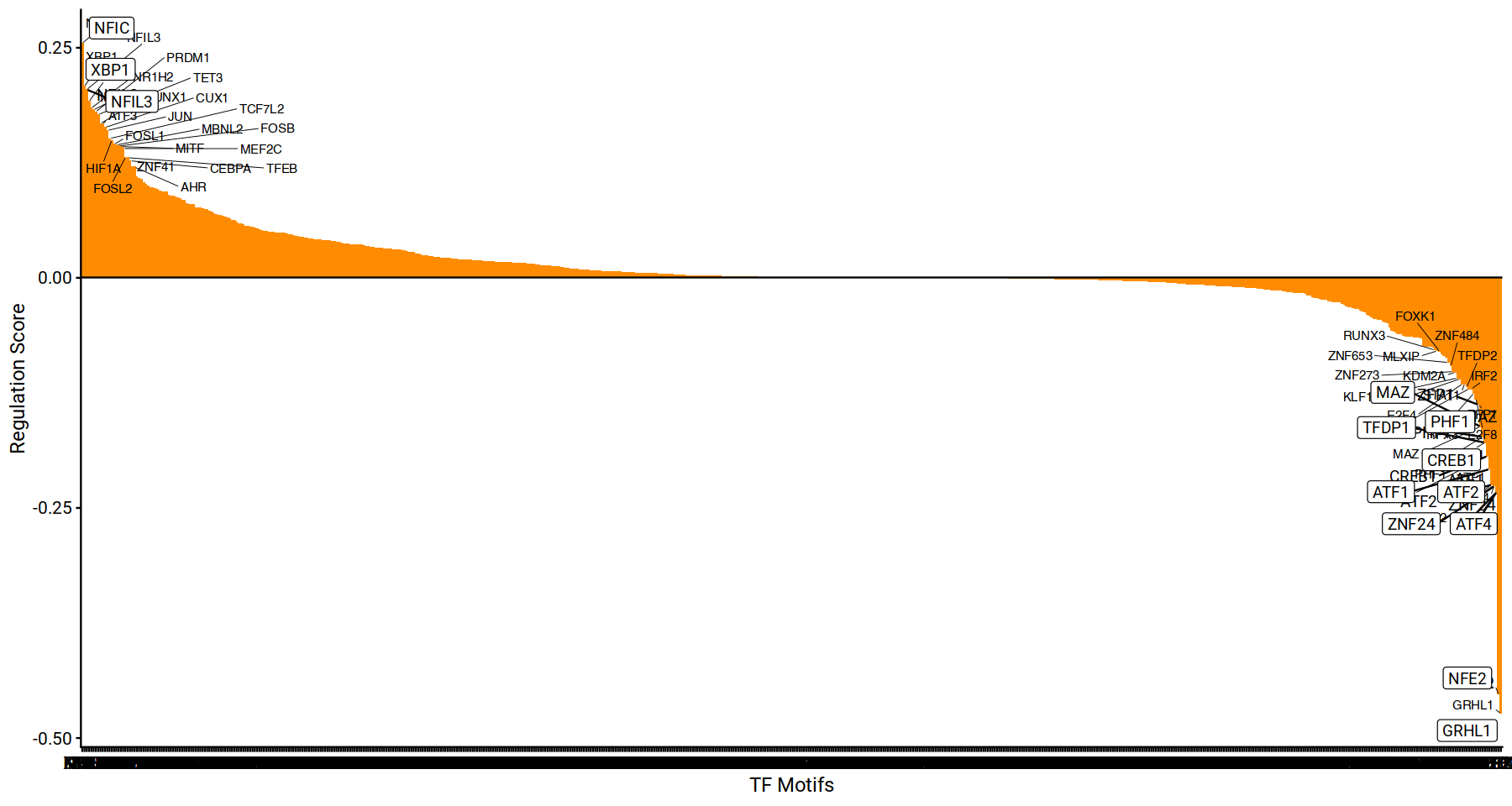
Rank based visualization of driver TFs, to get an intuitive positive-negative priority list of relevant TF candidates.
drivers <- rankDrivers(figR.d, rankBy = "meanScore",interactive = FALSE)
options(repr.plot.width=15, repr.plot.height=8)
drivers + geom_text_repel(family='roboto') + geom_label_repel(family='roboto') + cowplot::theme_cowplot(font_family='roboto') + labs(font_family='roboto')
Ranking TFs by mean regulation score across all DORCs ..
Warning message:
“ggrepel: 39 unlabeled data points (too many overlaps). Consider increasing max.overlaps”
Warning message:
“ggrepel: 51 unlabeled data points (too many overlaps). Consider increasing max.overlaps”
Warning message:
“ggrepel: 55 unlabeled data points (too many overlaps). Consider increasing max.overlaps”
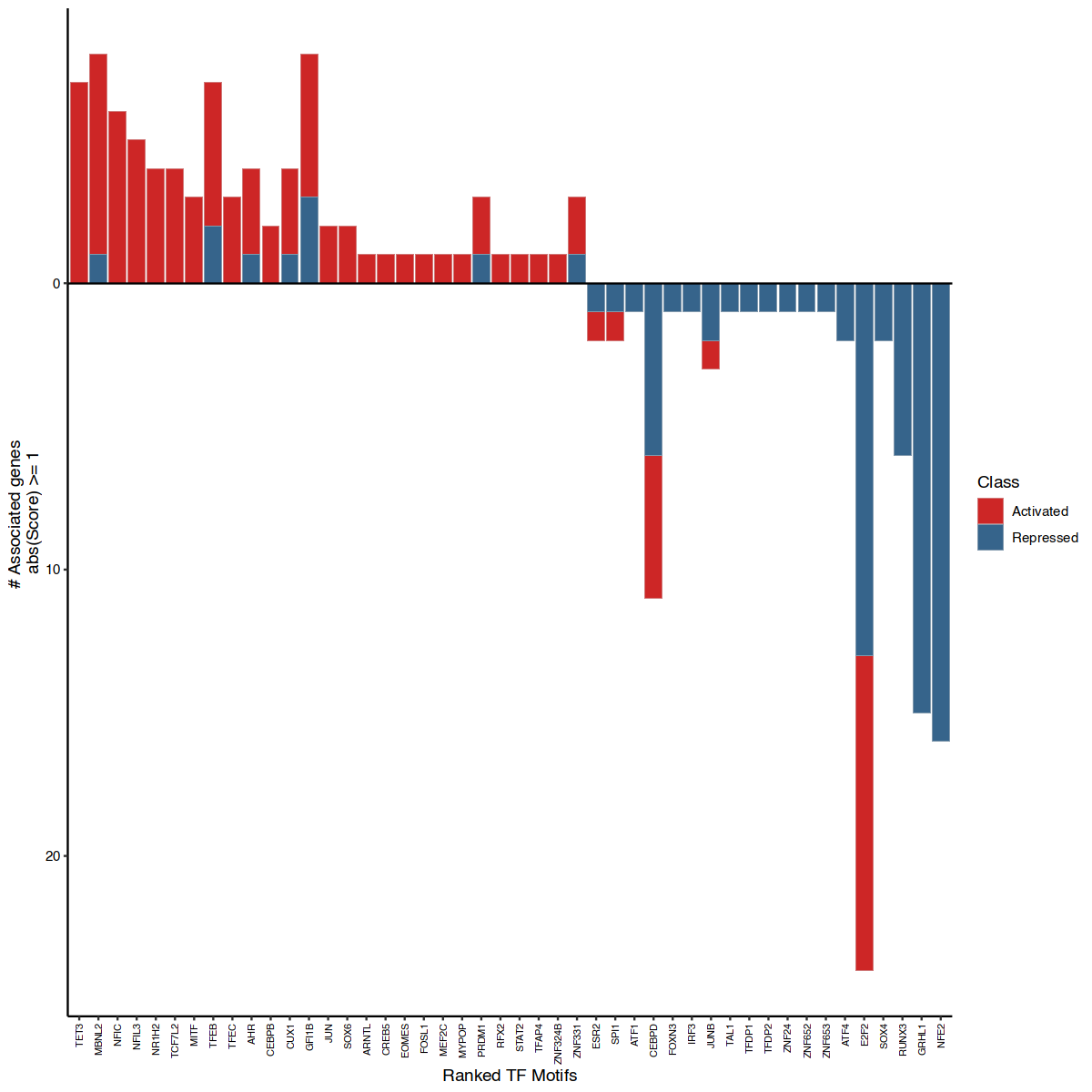
This next visualization attempts to visualize the relevant motifs annotated, by their associated number of target genes activated or repressed. This allows to observe the coverage of top-motifs potentially activating or repressing certain gene programs in the studied sample.
options(repr.plot.width=10, repr.plot.height=10)
rankDrivers(figR.d,score.cut = 1, rankBy = "nTargets", interactive = FALSE, fontsiz)
Ranking TFs by total number of associated DORCs ..
Using absolute score cut-off of: 1 ..
The following visualization is a heatmap-based visualization of DORC-scores for candidate TFs and strong genes they potentially regulate, based on TF-DORC-target gene associations. (Rows = Target genes, Columns = TF).
library(grid)
library(ComplexHeatmap)
options(repr.plot.width=10, repr.plot.height=10)
pushViewport(viewport(gp = gpar(fontfamily = "sans")));
heatmap <- plotfigRHeatmap(figR.d = figR.d,
score.cut = 1,
TFs = unique(figR.d$Motif),
column_names_gp = gpar(fontsize=10), # from ComplexHeatmap
show_row_dend = FALSE # from ComplexHeatmap
)
draw(heatmap, newpage = FALSE)
popViewport()
Using absolute score cut-off of: 1 ..
Using Score as value column: use value.var to override.
Plotting 45 DORCs x 46TFs
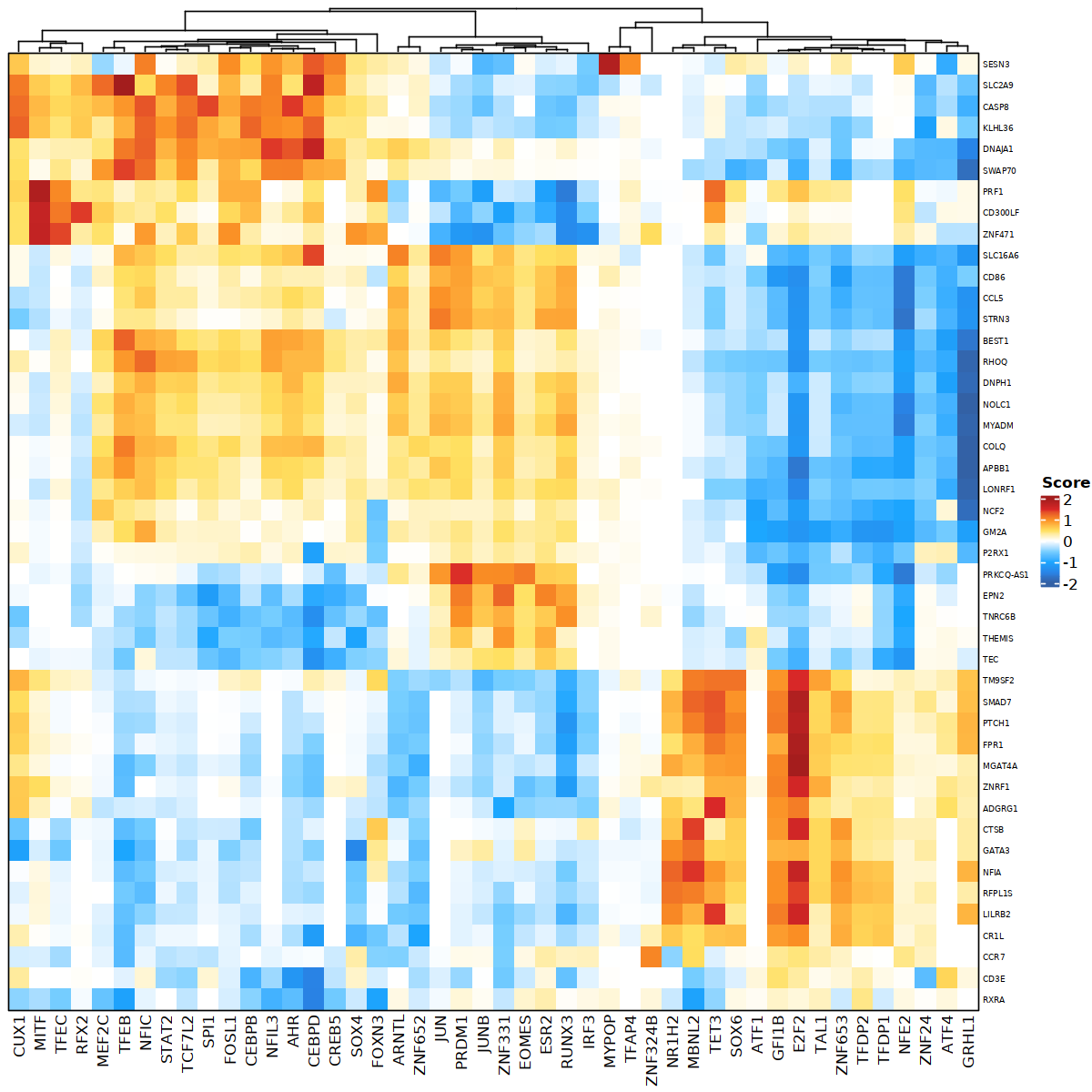
This visualization allows us to quickly identify the main TFs and their association with the regulation of potential target genes through DORCs in their genome neighborhoods.
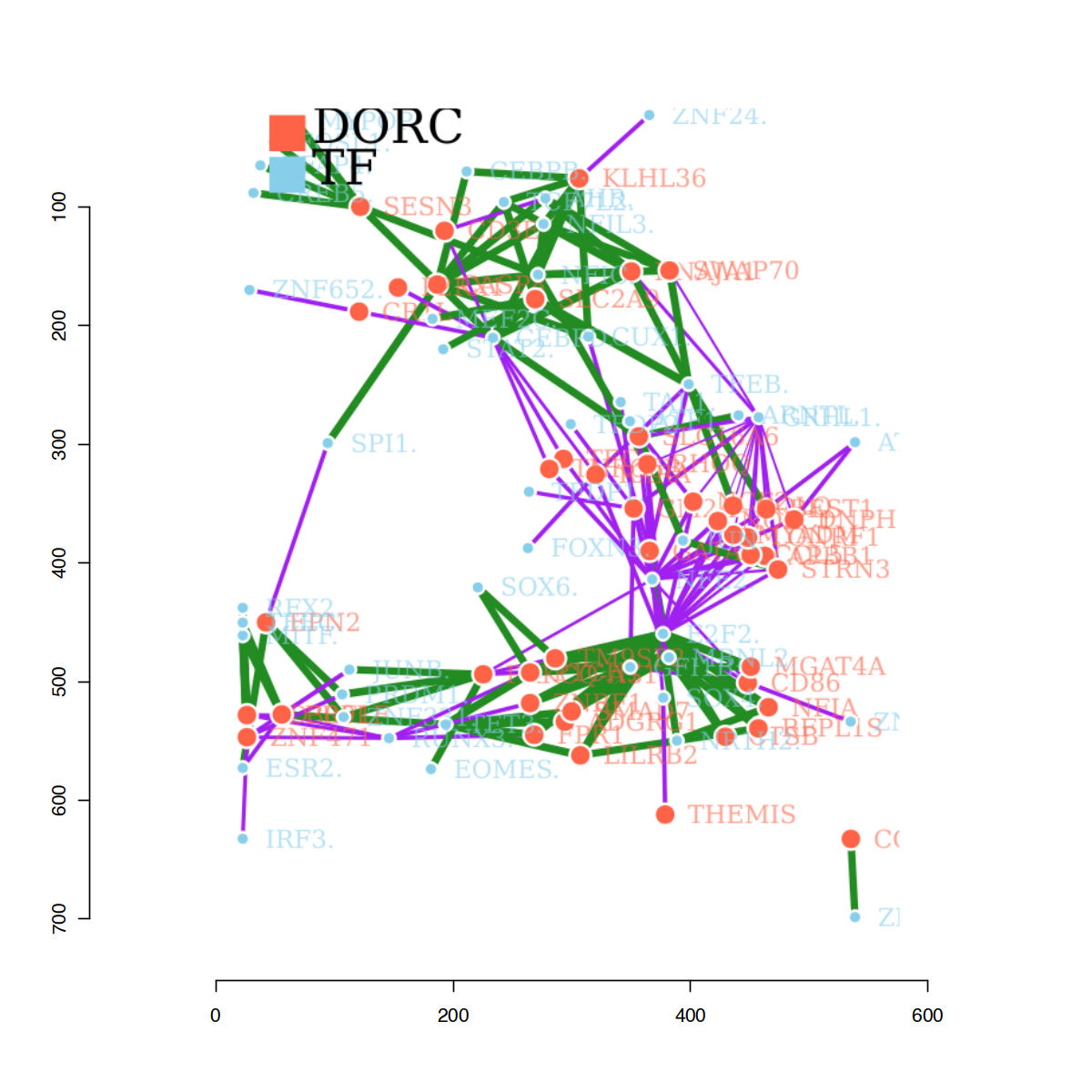
As a last exploratory visualization, a network of associations can also be retrieved, using the package networkD3. This allows exploring clusters of genes that are overlapping across TFs, and potentially overlapping regulons controlled by common-TFs.
library(networkD3)
library(r2d3)
library(imager)
# generate the network
d3 <- plotfigRNetwork(figR.d,
score.cut = 1,
TFs = unique(figR.d$Motif),
weight.edges = TRUE)
# in a local session, the network can be manipulated interactively
d3
27.2.1. Save network as HTML/PNG#
# If pandoc if not found by R, here the bin path in the environment has to be provided e.g. `envs/best_practices_regulons_rnanatac/bin`
# rmarkdown::find_pandoc(dir = "bin_path") # e.g. bin_path = '~/miniconda3/envs/best_practices_regulons_rnanatac/bin'
# is saved as an image and shown for exploratory purposes outside of this notebook
save_d3_html(
d3,
'network_tutorial_rna_n_atac.html',
)
# the network is saved as an image and shown for online purposes.
save_d3_png(
d3,
'network_tutorial_rna_n_atac.png',
width = 350,
height = 450,
delay = 4.0,
zoom = 1.6,
)
im <- load.image('network_tutorial_rna_atac.png')
plot(im)
Log of packages used to execute this notebook
sessionInfo()
R version 4.2.2 (2022-10-31)
Platform: x86_64-conda-linux-gnu (64-bit)
Running under: Ubuntu 20.04 LTS
Matrix products: default
BLAS/LAPACK: /home/rio/miniconda3/envs/best_practices_regulons_rnanatac/lib/libopenblasp-r0.3.21.so
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] grid parallel stats4 stats graphics grDevices utils
[8] datasets methods base
other attached packages:
[1] imager_0.42.19 magrittr_2.0.3
[3] r2d3_0.2.6 networkD3_0.4
[5] ComplexHeatmap_2.14.0 BuenColors_0.5.6
[7] MASS_7.3-58.3 patchwork_1.1.2
[9] ggrastr_1.0.1 doParallel_1.0.17
[11] iterators_1.0.14 foreach_1.5.2
[13] ggrepel_0.9.3 BSgenome.Hsapiens.UCSC.hg38_1.4.5
[15] BSgenome_1.66.3 rtracklayer_1.58.0
[17] Biostrings_2.66.0 XVector_0.38.0
[19] FNN_1.1.3.2 umap_0.2.10.0
[21] cisTopic_0.3.0 SingleCellExperiment_1.20.0
[23] zellkonverter_1.8.0 FigR_0.1.0
[25] motifmatchr_1.20.0 chromVAR_1.20.0
[27] cowplot_1.1.1 ggplot2_3.4.1
[29] dplyr_1.1.1 SummarizedExperiment_1.28.0
[31] Biobase_2.58.0 GenomicRanges_1.50.0
[33] GenomeInfoDb_1.34.9 IRanges_2.32.0
[35] S4Vectors_0.36.0 BiocGenerics_0.44.0
[37] MatrixGenerics_1.10.0 matrixStats_0.63.0
[39] Matrix_1.5-3
loaded via a namespace (and not attached):
[1] utf8_1.2.3 reticulate_1.26
[3] R.utils_2.12.2 tidyselect_1.2.0
[5] poweRlaw_0.70.6 RSQLite_2.3.0
[7] AnnotationDbi_1.60.2 htmlwidgets_1.6.2
[9] gmp_0.7-1 BiocParallel_1.32.5
[11] munsell_0.5.0 codetools_0.2-19
[13] DT_0.27 pbdZMQ_0.3-9
[15] miniUI_0.1.1.1 withr_2.5.0
[17] RcisTarget_1.18.2 colorspace_2.1-0
[19] filelock_1.0.2 knitr_1.42
[21] uuid_1.1-0 rstudioapi_0.14
[23] pbmcapply_1.5.1 labeling_0.4.2
[25] repr_1.1.6 GenomeInfoDbData_1.2.9
[27] lgr_0.4.4 bit64_4.0.5
[29] farver_2.1.1 rprojroot_2.0.3
[31] basilisk_1.9.12 vctrs_0.6.1
[33] generics_0.1.3 xfun_0.38
[35] float_0.3-1 R6_2.5.1
[37] clue_0.3-64 ggbeeswarm_0.7.1
[39] bitops_1.0-7 arrow_10.0.1
[41] cachem_1.0.7 DelayedArray_0.24.0
[43] assertthat_0.2.1 promises_1.2.0.1
[45] BiocIO_1.8.0 scales_1.2.1
[47] beeswarm_0.4.0 gtable_0.3.3
[49] Cairo_1.6-0 processx_3.8.0
[51] bmp_0.3 seqLogo_1.64.0
[53] rlang_1.1.0 GlobalOptions_0.1.2
[55] text2vec_0.6.3 splines_4.2.2
[57] lazyeval_0.2.2 yaml_2.3.7
[59] reshape2_1.4.4 httpuv_1.6.9
[61] tools_4.2.2 feather_0.3.5
[63] nabor_0.5.0 gplots_3.1.3
[65] ellipsis_0.3.2 RColorBrewer_1.1-3
[67] Rcpp_1.0.10 plyr_1.8.8
[69] base64enc_0.1-3 sparseMatrixStats_1.10.0
[71] zlibbioc_1.44.0 purrr_1.0.1
[73] RCurl_1.98-1.10 ps_1.7.3
[75] basilisk.utils_1.10.0 openssl_2.0.5
[77] GetoptLong_1.0.5 cluster_2.1.4
[79] here_1.0.1 data.table_1.14.8
[81] RSpectra_0.16-1 readbitmap_0.1.5
[83] circlize_0.4.15 mlapi_0.1.1
[85] fitdistrplus_1.1-8 hms_1.1.3
[87] mime_0.12 evaluate_0.20
[89] xtable_1.8-4 RhpcBLASctl_0.23-42
[91] XML_3.99-0.14 jpeg_0.1-10
[93] AUCell_1.20.2 shape_1.4.6
[95] compiler_4.2.2 tibble_3.2.1
[97] KernSmooth_2.23-20 crayon_1.5.2
[99] R.oo_1.25.0 htmltools_0.5.5
[101] tiff_0.1-11 later_1.3.0
[103] tzdb_0.3.0 TFBSTools_1.36.0
[105] snow_0.4-4 tidyr_1.3.0
[107] DBI_1.1.3 readr_2.1.4
[109] cli_3.6.1 R.methodsS3_1.8.2
[111] igraph_1.4.1 pkgconfig_2.0.3
[113] GenomicAlignments_1.34.0 rsparse_0.5.1
[115] dir.expiry_1.6.0 TFMPvalue_0.0.9
[117] IRdisplay_1.1 plotly_4.10.1
[119] annotate_1.76.0 lda_1.4.2
[121] vipor_0.4.5 DirichletMultinomial_1.40.0
[123] webshot_0.5.4 callr_3.7.3
[125] stringr_1.5.0 digest_0.6.31
[127] pracma_2.4.2 CNEr_1.34.0
[129] graph_1.76.0 rmarkdown_2.21
[131] DelayedMatrixStats_1.20.0 GSEABase_1.60.0
[133] restfulr_0.0.15 shiny_1.7.4
[135] Rsamtools_2.14.0 gtools_3.9.4
[137] rjson_0.2.21 lifecycle_1.0.3
[139] jsonlite_1.8.4 viridisLite_0.4.1
[141] askpass_1.1 fansi_1.0.4
[143] pillar_1.9.0 lattice_0.20-45
[145] KEGGREST_1.38.0 fastmap_1.1.1
[147] httr_1.4.5 survival_3.5-5
[149] GO.db_3.16.0 glue_1.6.2
[151] png_0.1-8 bit_4.0.5
[153] stringi_1.7.12 blob_1.2.4
[155] doSNOW_1.0.20 caTools_1.18.2
[157] memoise_2.0.1 Rmpfr_0.9-1
[159] IRkernel_1.3.2
27.3. Quiz#
27.3.1. Theory#
27.3.2. FigR#
27.4. References#
Carmen Bravo González-Blas, Liesbeth Minnoye, Dafni Papasokrati, Sara Aibar, Gert Hulselmans, Valerie Christiaens, Kristofer Davie, Jasper Wouters, and Stein Aerts. Cistopic: cis-regulatory topic modeling on single-cell ATAC-seq data. Nat. Methods, 16(5):397–400, May 2019.
Vinay K Kartha, Fabiana M Duarte, Yan Hu, Sai Ma, Jennifer G Chew, Caleb A Lareau, Andrew Earl, Zach D Burkett, Andrew S Kohlway, Ronald Lebofsky, and Jason D Buenrostro. Functional inference of gene regulation using single-cell multi-omics. Cell Genom, September 2022.
Alicia N Schep, Beijing Wu, Jason D Buenrostro, and William J Greenleaf. chromVAR: inferring transcription-factor-associated accessibility from single-cell epigenomic data. Nat. Methods, 14(10):975–978, October 2017.
François Spitz and Eileen E M Furlong. Transcription factors: from enhancer binding to developmental control. Nat. Rev. Genet., 13(9):613–626, 2012.
27.5. Contributors#
We gratefully acknowledge the contributions of:
27.5.2. Reviewers#
Lukas Heumos
Anna Schaar